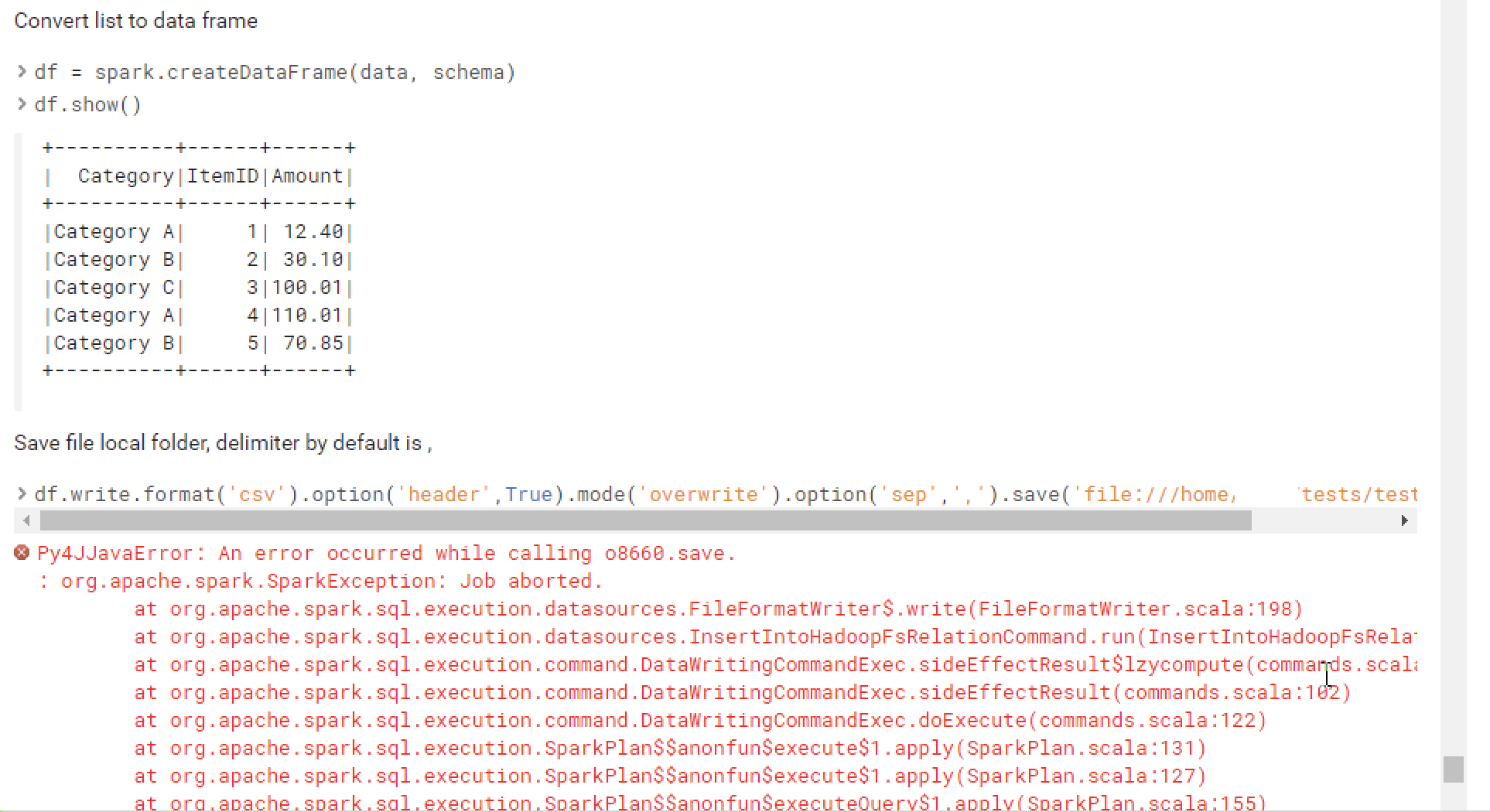
I want to save a csv file locally rather than saving it to Hadoop file system. I got the following error when I use the path that starts with
> 'file://'
How can I fixed this? Or How can I save the file locally without any errors?
CodePudding user response:
I'm afraid its not gonna work like that because saving the data locally implies it must all be present on the driver. Per pyspark docs, the path parameter in pyspark.sql.DataFrameWriter.csv is a "path in any Hadoop supported file system".
So as far as I can tell, there are several alternatives:
- Save dataframe to HDFS/Hadoop and then copy it to local FS
hdfs dfs -mget .... This would be most straightforward and preferred way. - Do
df.collect()to bring complete dataframe to the driver, and then write it to local FS. This might not be feasible for large dataframes, since it can crash the driver with OOM. - use
df.toLocalIterator()to bring data to the driver one partition at a time, and then write it to local FS. This avoids / lessens OOM chances presented by previous option.