Let say I have a base_df I wish to update with new data from new_df.
base_df could be a dataframe as the following. Where at some point FC and FF faults were removed, and that indexes were marked as Spare
base_df = pd.DataFrame({'Fault': ['FA','FB','Spare1','FD','FE','Spare2'],
'Description' : ['Des for FA','Des for FB','Des for FC','Des for FD',\
'Des for FE','Des for FF']})
base_df
Fault Description
0 FA Des for FA
1 FB Des for FB
2 Spare Des for FC
3 FD Des for FD
4 FE Des for FE
5 Spare Des for FF
In the new_df a fault could be missing (e.g. FB) and it could contain new rows (e.g.FG,FH,FI and FJ). However new_df will never contain nor NaN or Spare rows.
new_df = pd.DataFrame({'Fault': ['FA','FD','FE','FG','FH','FI'],
'Description' : ['Des for FA','Des for FD','Des for FE',\
'Des for FG','Des for FH','Des for FI']})
new_df
Fault Description
0 FA Des for FA
1 FD Des for FD
2 FE Des for FE
3 FG Des for FG
4 FH Des for FH
5 FI Des for FI
6 FJ Des for FJ
To update base_df with new_df the following rules should be followed:
- If in
new_dfis missing a fault that appears inbase_df, it is marked as Spare inupdated_df. - If in
new_dfare new faults, first it should fill Spare rows. If there are not spare rows, they can be added to the end.
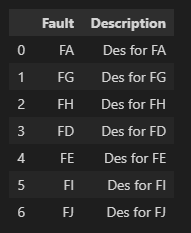
With the previous example, the updated_df should finish as per below.
updated_df = pd.DataFrame({'Fault': ['FA','FG','FH','FD','FE','FI','FJ'],
'Description' : ['Des for FA','Des for FG','Des for FH','Des for FD',\
'Des for FE','Des for FI','Des for FJ']})
updated_df
Fault Description
0 FA Des for FA
1 FG Des for FG
2 FH Des for FH
3 FD Des for FD
4 FE Des for FE
5 FI Des for FI
6 FJ Des for FJ
ADDITIONAL INFORMATION
Description for Spare rows can be removed, set as Nan or the easyest value to work with
In a second step I would like also to mark the new added rows in green and the deleted rows saved in a df apart
CodePudding user response:
The solution is:
fault1=list(base_df.Fault)
fault2=list(new_df.Fault)
i=0
updated_df=base_df
for k in fault1:
i=i 1
if k not in fault2:
updated_df.loc[i-1,'Fault']="Spare"
updated_df.loc[i-1,'Description']="Spare"
for k in fault2:
if k not in list(updated_df.Fault):
try:
i=list(updated_df.Fault).index('Spare')
updated_df.loc[i,'Fault']=k
updated_df.loc[i,'Description']=new_df[new_df.Fault==k].Description.values[0]
except:
updated_df.loc[len(updated_df.index)]=[k,new_df[new_df.Fault==k].Description.values[0]]
updated_df