I am creating a binary classifier in R, but I don't know what probability threshold to select for class separation. The code is as follows:
tune.out <-
tune(svm, X0 ~ .,
data = data.frame(y = as.vector(class_train), model_train),
kernel = "polynomial", ranges = list(cost = c(0.001,0.01,0.1, 1,5,10,100)))
bestmod <-
tune.out$best.model
Index <-
order(class_train, decreasing = FALSE)
SVMfit_Var <-
svm(model_train[Index, ], class_train[Index, ],
type= "eps-regression",kernel = "polynomial", cost = bestmod$cost, gamma=bestmod$gamma, epsilon = bestmod$epsilon, scale=F)
preds1 <-
predict(SVMfit_Var, Xtest, probability = TRUE)
preds1 <-
attr(preds1, "probabilities")[,1]
prediction <- predict(SVMfit_Var, model_valid, probability = T)
xtab <- table(t(class_valid), prediction)
inf.pred <- rep(0, dim(model_valid)[1])
inf.pred[prediction > 0.5] = 1
performance <- Conf(table(inf.pred, t(class_valid)))
Right now I have a threshold of 0.5. The problem is that the calculated probabilities are all 0.1.
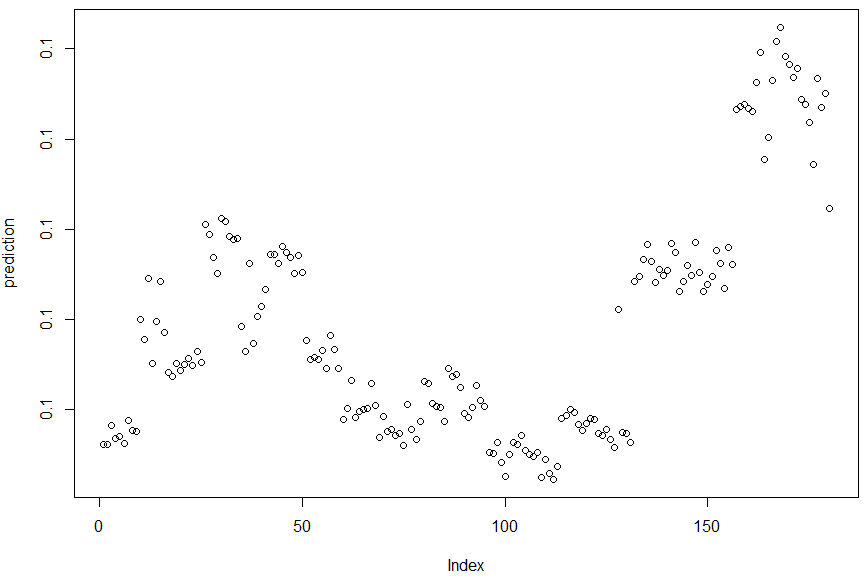
The values displayed are 0.1, although there seem to be decimals that are not displayed. In this case, the index values 1-145 are class 0, and 145-180 class 1.
How can I set an optimal threshold for the classifier?
CodePudding user response:
One approach could be to base the threshold on the proportion of positive classes seen in your training data. For example, if 20% of cases in your training data have a positive class, then you could pick the same proportion of cases in your test data, classifying the 20% with the highest probabilities as positive.
Whether this approach is appropriate or not really depends on your classification problem. The model can tell you the probability of a case being positive or negative - how you decide to use those probabilities to make a classification is a question to be considered outside of the modelling, and really depends on the cost of mis-classifying in your particular case.