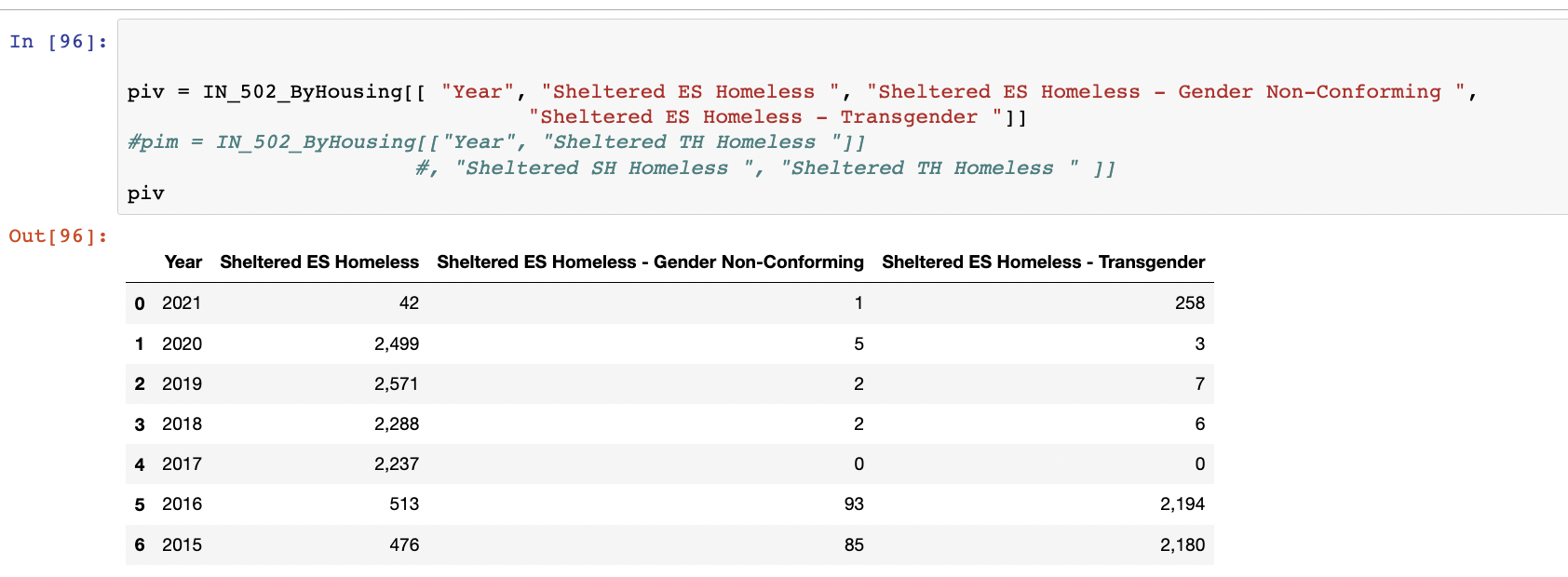
In the above dataframe, all I want to create a line plot so that we have info on trends per year for each of the columns. I've read about pivot-table on related posts, but when I implement that, it says there are no numbers to aggregate. I don't want to aggregate something. I just need the y-axis in terms of the column numbers.
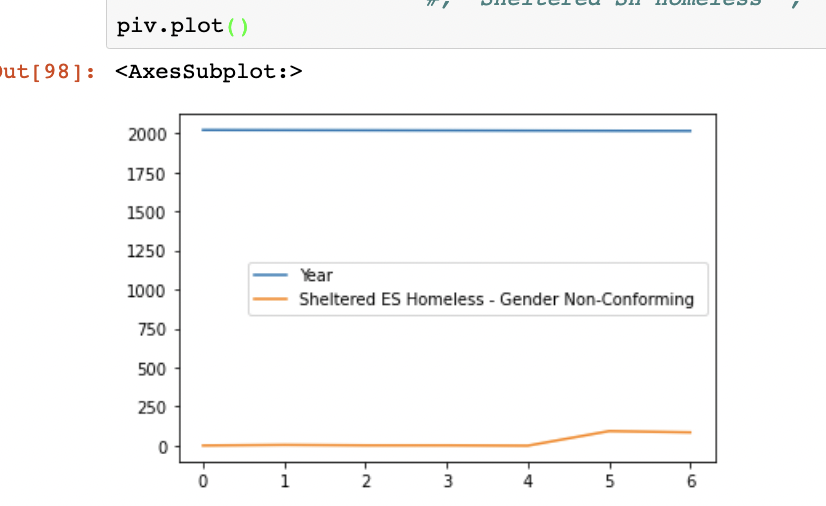
When I use plot() however, it plots year on the x-axis and only plots other column also on the x-axis. Why is this happening and what I am doing wrong?
CodePudding user response:
Welcome to stackoverflow, please do not use image of code and data
Quick Answer
# change the type of non numeric
piv['second_col'] = piv['second_col'].str.replace(',','').astype(float)
piv['last_col'] = piv['last_col'].str.replace(',','').astype(float)
# then plot
piv.plot(x='Year')
Explanation
The index of the Dataframe is the default x-axis, So you need to specify :
piv.plot(x='Year')
Or set the Year as index :
piv.set_index('Year').plot()
One more thing is that the plot function plot numeric values, the second and last columns type is string you can check :
df.dtypes
When you use pandas.read_csv to read a file it has to infer the data type. Sometimes it gets it wrong. You can forces pandas to try and convert the data to floating point numbers :
piv = piv.astype(float)
But you will get an error somthing like this :
ValueError: could not convert string to float: '2,499'
But Why ?
The data has a comma-separated numeric value, you need to remove it before converting to float
piv['name_of_column'] = piv['name_of_column'].str.replace(',','').astype(float)