I have data that looks like this (from jq)
script_runtime{application="app1",runtime="1651394161"} 1651394161
folder_put_time{application="app1",runtime="1651394161"} 22
folder_get_time{application="app1",runtime="1651394161"} 128.544
folder_ls_time{application="app1",runtime="1651394161"} 3.868
folder_ls_count{application="app1",runtime="1651394161"} 5046
The dataframe should allow manipulation of each row to this:
script_runtime,app1,1651394161,1651394161
folder_put_time,app1,1651394161,22
Its in a textfile. How can I easily load it into pandas for data manipulation?
CodePudding user response:
- Load the .txt using pd.read_csv(), specifying a space as the separator (
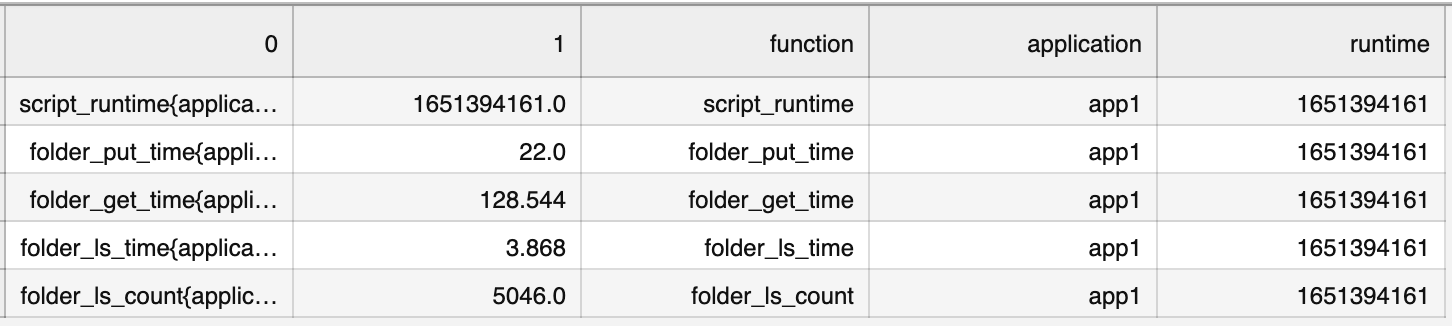
If you want to drop the first column which contains the bracketed value:
df = df.iloc[: , 1:]
Full code:
df = pd.read_csv("textfile.txt", header=None, delimiter=r"\s ") df['function'] = df[0].str.split("{",expand=True)[0] df['application'] = df[0].str.split("\"",expand=True)[1] df['runtime'] = df[0].str.split("\"",expand=True)[3] df = df.iloc[: , 1:]