I have a dataset with names of organisations and codes. Some organisations have multiple codes, some have only one code. I want to make a set that shows the organisation in one column, and all the codes of that organisation in another column.
This is how the dataset is right now:
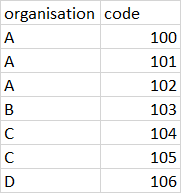
And this is how it should be:
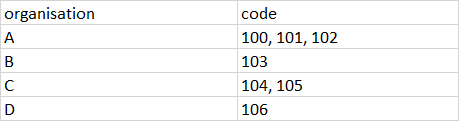
Does anyone know what script in Python I could use for this?
CodePudding user response:
df.groupby("organisation").code.apply(list)
Note that it produce a pd.Series. If you want to convert it in a pd.DataFrame use the .to_frame() method.
CodePudding user response:
You can try
out = (df.astype({'code': str})
.groupby('organisation', as_index=False)['code']
.apply(', '.join))
print(out)
organisation code
0 A 100, 101, 102
1 B 103
2 C 104, 105
3 D 106