I have a pandas DataFrame with values in columns A, B, C, and D and want to determine for every row the first and last non-zero column. BUT the order of the elements is not the same for all rows. It is determined by columns item_0, item_1 and item_2.
While I can easily do this by applying a function to every row this becomes very slow for my DataFrame. Is there an elegant, more pythonic / pandasy way to do this?
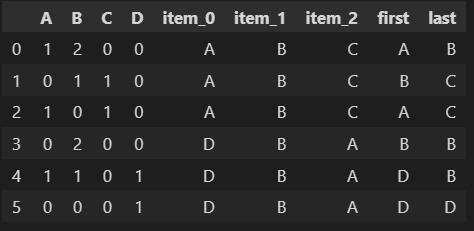
Input:
A B C D item_0 item_1 item_2
0 1 2 0 0 A B C
1 0 1 1 0 A B C
2 1 0 1 0 A B C
3 0 2 0 0 D A B
4 1 1 0 1 D A B
5 0 0 0 1 D A B
Expected Output:
A B C D item_0 item_1 item_2 first last
0 1 2 0 0 A B C A B
1 0 1 1 0 A B C B C
2 1 0 1 0 A B C A C
3 0 2 0 0 D A B B B
4 1 1 0 1 D A B D B
5 0 0 0 1 D A B D D
Update: Here's the current code with apply
import pandas as pd
def first_and_last_for_row(row):
reference_list = row[["item_0", "item_1", "item_2"]].tolist()
list_to_sort = (
row[["A", "B", "C", "D"]].index[row[["A", "B", "C", "D"]] > 0].tolist()
)
ordered_list = [l for l in reference_list if l in list_to_sort]
if len(ordered_list) == 0:
return None, None
else:
return ordered_list[0], ordered_list[-1]
df = pd.DataFrame(
{
"A": [1, 0, 1, 0, 1, 0],
"B": [2, 1, 0, 2, 1, 0],
"C": [0, 1, 1, 0, 0, 0],
"D": [0, 0, 0, 0, 1, 1],
"item_0": ["A", "A", "A", "D", "D", "D"],
"item_1": ["B", "B", "B", "A", "A", "A"],
"item_2": ["C", "C", "C", "B", "B", "B"],
}
)
df[["first", "last"]] = df.apply(first_and_last_for_row, axis=1, result_type="expand")
CodePudding user response:
Here is a fully vectorized numpy approach. It's not very complex but has quite a few steps so I also provided a commented version of the code:
cols = ['A', 'B', 'C', 'D']
a = df[cols].to_numpy()
idx = df.filter(like='item_').replace({k:v for v,k in enumerate(cols)}).to_numpy()
b = a[np.arange(len(a))[:,None], idx] != 0
first = b.argmax(1)
last = b.shape[1]-np.fliplr(b).argmax(1)-1
c = df.filter(like='item_').to_numpy()
df[['first', 'last']] = c[np.arange(len(c))[:,None],
np.vstack((first, last)).T]
mask = b[np.arange(len(b)), first]
df[['first', 'last']] = df[['first', 'last']].where(pd.Series(mask, index=df.index))
commented code:
cols = ['A', 'B', 'C', 'D']
# convert to numpy array
a = df[cols].to_numpy()
# array([[1, 2, 0, 0],
# [0, 1, 1, 0],
# [1, 0, 1, 0],
# [0, 2, 0, 0],
# [1, 1, 0, 1],
# [0, 0, 0, 1]])
# get indexer as numpy array
idx = df.filter(like='item_').replace({k:v for v,k in enumerate(cols)}).to_numpy()
# array([[0, 1, 2],
# [0, 1, 2],
# [0, 1, 2],
# [3, 0, 1],
# [3, 0, 1],
# [3, 0, 1]])
# reorder columns and get non-zero
b = a[np.arange(len(a))[:,None], idx] != 0
# array([[ True, True, False],
# [False, True, True],
# [ True, False, True],
# [False, False, True],
# [ True, True, True],
# [ True, False, False]])
# first non-zero
first = b.argmax(1)
# array([0, 1, 0, 2, 0, 0])
# last non-zero
last = b.shape[1]-np.fliplr(b).argmax(1)-1
# array([1, 2, 2, 2, 2, 0])
# get back column names from position
c = df.filter(like='item_').to_numpy()
df[['first', 'last']] = c[np.arange(len(c))[:,None],
np.vstack((first, last)).T]
# optional
# define a mask in case a zero was selected
mask = b[np.arange(len(b)), first]
# array([ True, True, True, True, True, True])
# mask where argmax was 0
df[['first', 'last']] = df[['first', 'last']].where(pd.Series(mask, index=df.index))
output:
A B C D item_0 item_1 item_2 first last
0 1 2 0 0 A B C A B
1 0 1 1 0 A B C B C
2 1 0 1 0 A B C A C
3 0 2 0 0 D A B B B
4 1 1 0 1 D A B D B
5 0 0 0 1 D A B D D
CodePudding user response:
Let me try with a first attempt to "optimize", just by avoiding inner looping. The solution here is about 1.7x faster on 60k rows (I didn't have the patience to wait for 600k)
def first_and_last(row):
# select order given by items
i0, i1, i2 = items = np.array(row[["item_0", "item_1", "item_2"]])
# select values in right order
v0, v1, v2 = values = np.array(row[[i0, i1, i2]])
pos_values = (values > 0)
n_positives = np.sum(values)
if n_positives == 0:
return np.nan, np.nan
else:
return items[pos_values][[0, -1]]
Then:
df_ = pd.concat([df]*10_000)
# Original function
%time df_.apply(first_and_last_for_row, axis=1, result_type="expand")
CPU times: user 53.3 s, sys: 22.5 ms, total: 53.4 s
Wall time: 53.4 s
# New function
%time df_.apply(first_and_last, axis=1, result_type="expand")
CPU times: user 32.9 s, sys: 0 ns, total: 32.9 s
Wall time: 32.9 s
However, apply method is not optimal, there are other ways to iterate over a dataframe. In particular, you can use