I have a pandas dataframe df which looks as follows:
Base Current level New fan New refrigerator Unplug unused appliances Run washing machine with full load Fix leakages After three months Install smart thermostat Replace light bulbs with LED lights Replace desktop with laptop After six months
0 0 150.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
1 150 0.0 10.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
2 160 0.0 0.0 15.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
3 160 0.0 0.0 0.0 15.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
4 145 0.0 0.0 0.0 0.0 15.0 0.0 0.0 0.0 0.0 0.0 0.0
5 140 0.0 0.0 0.0 0.0 0.0 5.0 0.0 0.0 0.0 0.0 0.0
6 0 0.0 0.0 0.0 0.0 0.0 0.0 140.0 0.0 0.0 0.0 0.0
7 115 0.0 0.0 0.0 0.0 0.0 0.0 0.0 25.0 0.0 0.0 0.0
8 105 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 10.0 0.0 0.0
9 95 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 10.0 0.0
10 0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 95.0
df.to_dict() is given for reference:
{'Base': {0: 0,
1: 150,
2: 160,
3: 160,
4: 145,
5: 140,
6: 0,
7: 115,
8: 105,
9: 95,
10: 0},
'Current level': {0: 150.0,
1: 0.0,
2: 0.0,
3: 0.0,
4: 0.0,
5: 0.0,
6: 0.0,
7: 0.0,
8: 0.0,
9: 0.0,
10: 0.0},
'New fan': {0: 0.0,
1: 10.0,
2: 0.0,
3: 0.0,
4: 0.0,
5: 0.0,
6: 0.0,
7: 0.0,
8: 0.0,
9: 0.0,
10: 0.0},
'New refrigerator': {0: 0.0,
1: 0.0,
2: 15.0,
3: 0.0,
4: 0.0,
5: 0.0,
6: 0.0,
7: 0.0,
8: 0.0,
9: 0.0,
10: 0.0},
'Unplug unused appliances': {0: 0.0,
1: 0.0,
2: 0.0,
3: 15.0,
4: 0.0,
5: 0.0,
6: 0.0,
7: 0.0,
8: 0.0,
9: 0.0,
10: 0.0},
'Run washing machine with full load': {0: 0.0,
1: 0.0,
2: 0.0,
3: 0.0,
4: 15.0,
5: 0.0,
6: 0.0,
7: 0.0,
8: 0.0,
9: 0.0,
10: 0.0},
'Fix leakages': {0: 0.0,
1: 0.0,
2: 0.0,
3: 0.0,
4: 0.0,
5: 5.0,
6: 0.0,
7: 0.0,
8: 0.0,
9: 0.0,
10: 0.0},
'After three months': {0: 0.0,
1: 0.0,
2: 0.0,
3: 0.0,
4: 0.0,
5: 0.0,
6: 140.0,
7: 0.0,
8: 0.0,
9: 0.0,
10: 0.0},
'Install smart thermostat': {0: 0.0,
1: 0.0,
2: 0.0,
3: 0.0,
4: 0.0,
5: 0.0,
6: 0.0,
7: 25.0,
8: 0.0,
9: 0.0,
10: 0.0},
'Replace light bulbs with LED lights': {0: 0.0,
1: 0.0,
2: 0.0,
3: 0.0,
4: 0.0,
5: 0.0,
6: 0.0,
7: 0.0,
8: 10.0,
9: 0.0,
10: 0.0},
'Replace desktop with laptop': {0: 0.0,
1: 0.0,
2: 0.0,
3: 0.0,
4: 0.0,
5: 0.0,
6: 0.0,
7: 0.0,
8: 0.0,
9: 10.0,
10: 0.0},
'After six months': {0: 0.0,
1: 0.0,
2: 0.0,
3: 0.0,
4: 0.0,
5: 0.0,
6: 0.0,
7: 0.0,
8: 0.0,
9: 0.0,
10: 95.0}}
I want to plot a waterfall chart using this data. For this, I plotted a stacked bar plot using the code below and using column Base as bottom.
colors = ["royalblue","green","green","red","red","red","royalblue",
"red","red","red","royalblue"]
fig = df.loc[:,"Current level":].plot(kind = "bar",
bottom = df["Base"],
color = colors)
selected_patches = fig.patches[0], fig.patches[20], fig.patches[40]
plt.legend(selected_patches, ["Base", "Rise", "Fall"], loc = "upper right")
plt.xticks(ticks = np.arange(0, len(df)), labels = df.columns[1:], rotation = 90)
plt.title("My electricity saving plan")
plt.ylabel("kWh consumption")
This returned me the following plot:
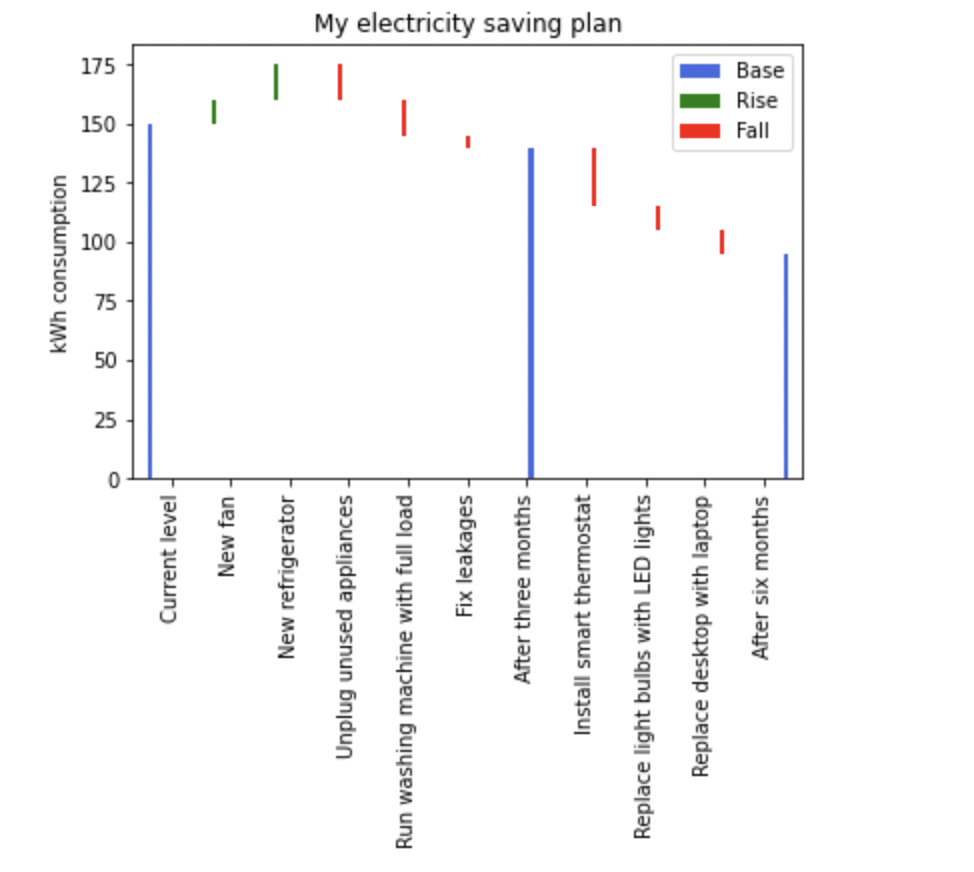
The default width of the bar plot i.e. 0.8 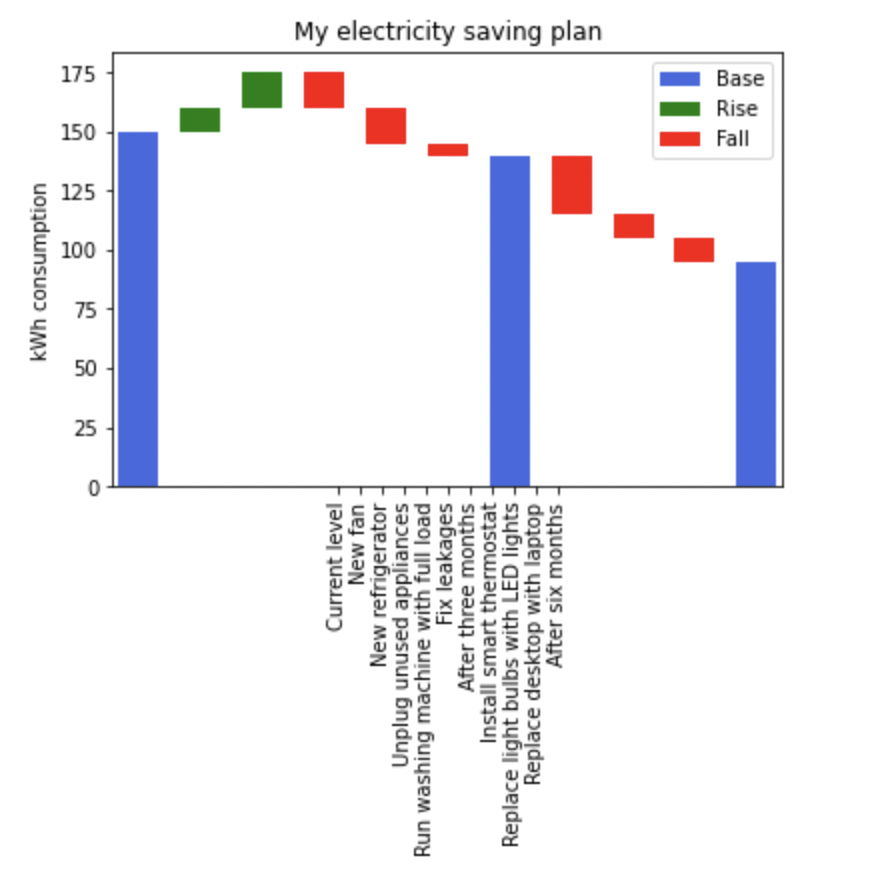
However, now the position of ticks and labels is distorted. How can I set the width of the bars such that the bars look wide, the space between bars is none or small, and the ticks and labels in the x-axis are still in the same position as bars?
CodePudding user response:
The problem is that each point in the x axis is allocating space for 10 different bars. So any size you put, you will always have 9 empty spaces. Instead, you should restructure the df before plotting:
import matplotlib.pyplot as plt
colors = ["royalblue","green","green","red","red","red","royalblue",
"red","red","red","royalblue"]
fig = df.loc[:,"Current level":].T.max(axis=1).plot(kind='bar', bottom=df['Base'], width=1, color=colors)
selected_patches = fig.patches[0], fig.patches[2], fig.patches[4]
plt.legend(selected_patches, ["Base", "Rise", "Fall"], loc = "upper right")
plt.xticks(ticks = np.arange(0, len(df)), labels = df.columns[1:], rotation = 90)
plt.title("My electricity saving plan")
plt.ylabel("kWh consumption")
plt.show()
Result:
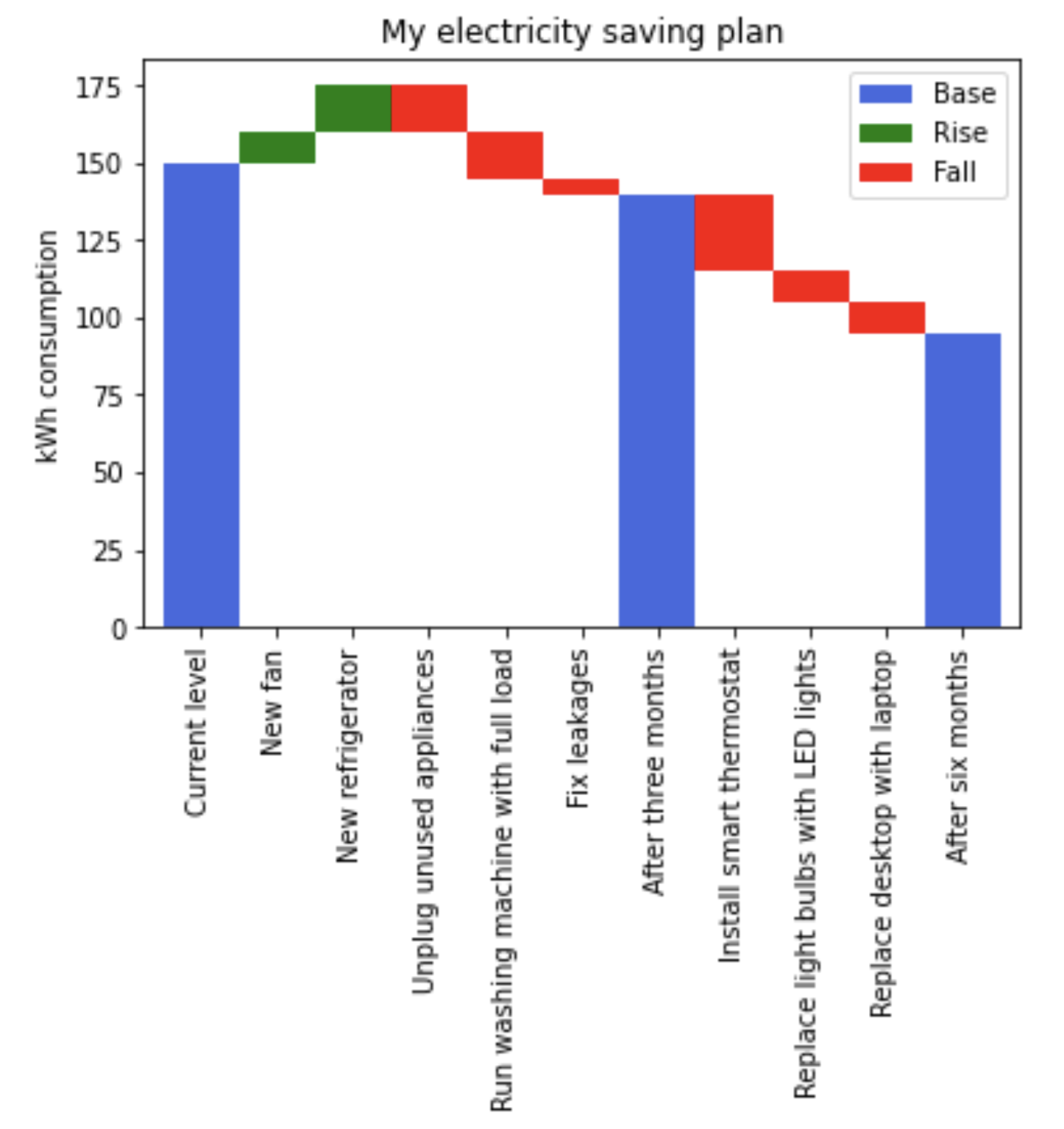
Notice that the patches indices also changed, since we don't have all the empty ones anymore.