I have some input data:
data = [('15.05.2022 12:36', 46879, 'Clinton Bill', '555-55-55', 'USA, White House', 'Cond', 'id_1', '56', 10),
('15.05.2022 12:36', 46879, 'Clinton Bill', '555-55-55', 'USA, White House', 'Cond', 'id_1', '56', 1),
('15.05.2022 12:36', 46879, 'Clinton Bill', '555-55-55', 'USA, White House', 'Lub', 'id_2', '45', 5),
('15.05.2022 13:00', 33990, 'Monika L.', '666-66-66', 'USA, Pennsylvania Av', 'Cond', 'id_1', '56', 7),
('15.05.2022 13:00', 33990, 'Monika L.', '666-66-66', 'USA, Pennsylvania Av', 'Lub', 'id_2', '45', 3),
('15.05.2022 13:00', 33990, 'Monika L.', '666-66-66', 'USA, Pennsylvania Av', 'Lub', 'id_2', '45', 9)]
The row items are:
(date, user_id, user_name, user_phone, user_address, product_name, product_id, product_price, product_count)
I should group data by user_id to represent info about every UNIQUE user, where count of the same products will be increminated, using python 3 script.
Smth like that:
output_data = [('15.05.2022 12:36', 46879, 'Clinton Bill', '555-55-55', 'USA, white house', ('Con', 'id_1', '56', 11), ('Lub','id_2', '45', 5)),
('15.05.2022 13:00', 33990, 'Monika L.', '666-66-66', 'Colorado', ('Con', 'id_1', '56', 7), ('Lub', 'id_2', '45', 12))]
Or may be you will sugest some better ways of performing output data. I'm going to send it via bot to admins.
CodePudding user response:
I think you can group your data by unique ids and then calculate the product sum. Based on this output you can easily create your structure.
import collections
output_data = dict()
for date, user_id, user_name, user_phone, user_address, product_name, product_id, product_price, product_count in data:
if not output_data.get(user_id):
output_data[user_id] = collections.defaultdict(int)
output_data[user_id][product_id] = product_count
print(output_data)
CodePudding user response:
Pandas style:
# convert your data to dataframe
df = pd.DataFrame(data, columns=columns)
columns_minus_one = list(df.columns[:-1])
df2 = df.groupby(columns_minus_one , as_index=False).sum('product_count')
Output:
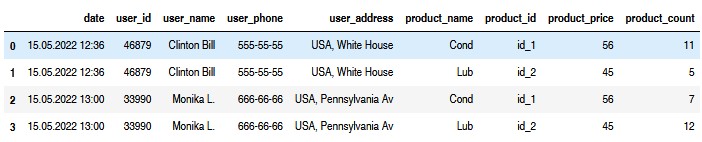
Then you can get back list:
df2.values.tolist()
CodePudding user response:
You can use itertools.groupby and operator.itemgetter twice (first is to groupby customers, second is to groupby products) to get the desired output. Here is the code.
import itertools
import operator
def my_groupby(lst, by_keys, return_keys):
getter = operator.itemgetter(*by_keys)
returner = operator.itemgetter(*return_keys)
# If the data is not sorted, sort it by by_keys to make the groupby work properly
sorted_data = sorted(lst, key=getter)
it = itertools.groupby(sorted_data, key=getter)
for key, subiter in it:
# Yield the key as list and desired columns from the data
yield list(key), [returner(item) for item in subiter]
res = my_groupby(data, by_keys=range(5), return_keys=range(5, 9))
output_data =[]
for customer in res:
prod = list(my_groupby(customer[1], by_keys=range(3), return_keys=[3]))
prod_total = list(map(lambda x: (*x[0], sum(x[1])), prod))
output_data.append(customer[0] prod_total)
print(output_data)
Output:
[['15.05.2022 12:36', 46879, 'Clinton Bill', '555-55-55', 'USA, White House', ('Cond', 'id_1', '56', 11), ('Lub', 'id_2', '45', 5)]
['15.05.2022 13:00', 33990, 'Monika L.', '666-66-66', 'USA, Pennsylvania Av', ('Cond', 'id_1', '56', 7), ('Lub', 'id_2', '45', 12)]]
The variable res has data grouped by customer details (column number 0 to 5) along with the products detail.
The next loop is to groupby the product details. prod will have product details and product counts. The total product counts were calculated using the map function. The calculated results were appended in an empty list, output_data to get the desired output.