If the following code works and equates to 'True':
'1234567' in '1234567:AMC'
Why won't it work in the following arrays/data-frames/columns?
import pandas as pd
x = {'Non-Suffix' : ['1234567', '1234568', '1234569', '1234554'], 'Suffix' : ['1234567:C', '1234568:VXCF', '1234569-01', '1234554-01:XC']}
x = pd.DataFrame(x)
x
x['Non-Suffix'] in x['Suffix']
# Note: Above line provides error (see below SO screen shot for full error)
Below is the error message I get:
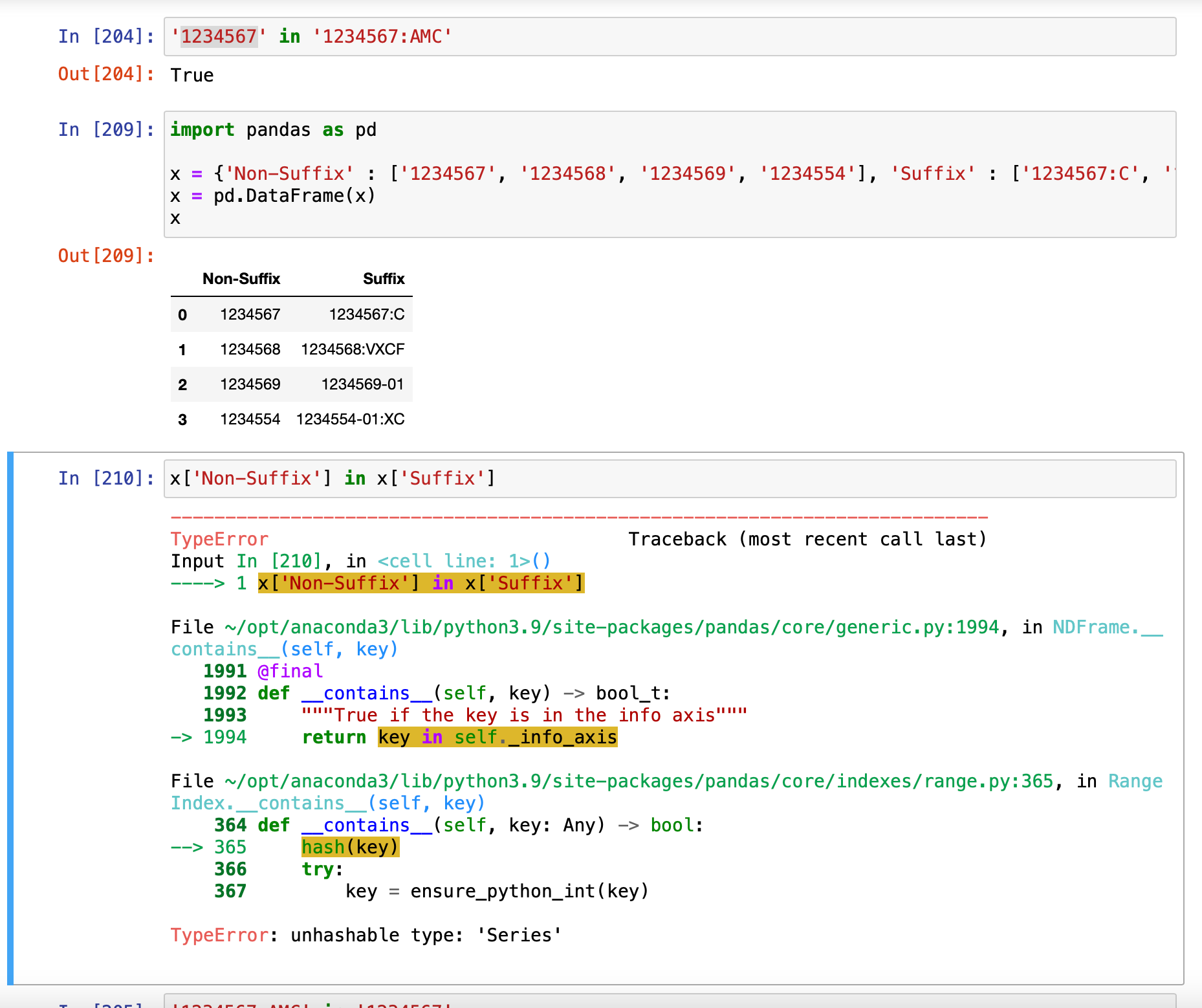
Is there a way be able to apply the '1234567' in '1234567:AMC' logic to columns of data?
CodePudding user response:
You can use apply() to perform the test row-wise
x.apply(lambda row: row['Non-Suffix'] in row['Suffix'], axis=1)
CodePudding user response:
You are using the in command on a <class 'pandas.core.series.Series'> which is not possible as the interpreter tells you. You have to access the underlying data arrays by using the array in the pandas dataframe by x['Non-Suffix'].array. Then you get the underlying <class 'pandas.core.arrays.numpy_.PandasArray'> for which in is implemented. So like this it will work
import pandas as pd
x = {'Non-Suffix' : ['1234567', '1234568', '1234569', '1234554'],
'Suffix' : ['1234567:C', '1234568:VXCF', '1234569-01', '1234554-01:XC']}
x = pd.DataFrame(x)
y = x['Non-Suffix'].array
print( type( y ) )
print( y )
x['Non-Suffix'].array in x['Suffix'].array