I have a HUGE dataset and I'm looking to improve ways to work more efficient with it. One alternative is replacing strings (ids) by integers. However, I need to do this transformation in the most efficient (less RAM used) way. Currently I would do:
import pandas as pd
df = pd.DataFrame({'Customer_ID': ['AWE','GRA', 'GRA', 'FAOOS', '1293912ASJDAS', '1293912ASJDAS', '1293912ASJDAS'],
'X2': [76,858,68,678,8678,78,6788],
'X3': [312,3123,123,54,3523,56,2346]})
unique_ids = df['Customer_ID'].drop_duplicates().tolist()
df_ = pd.DataFrame({'unique_ids': unique_ids,
'int_ids': list(range(0,len(unique_ids)))
})
df.merge(df_, how='left', left_on='Customer_ID', right_on='unique_ids').drop(['Customer_ID', 'unique_ids'], axis=1)
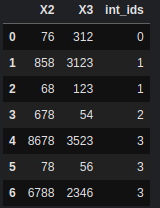
But it takes too long (the real data has 20M rows) and a lot of RAM, it's any way to improve this? (Any efficient package is welcome for this specific task)
CodePudding user response:
use
df['id'] = df.Customer_ID.astype('category').cat.codes
df
Customer_ID X2 X3 id
0 AWE 76 312 1
1 GRA 858 3123 3
2 GRA 68 123 3
3 FAOOS 678 54 2
4 1293912ASJDAS 8678 3523 0
5 1293912ASJDAS 78 56 0
6 1293912ASJDAS 6788 2346 0