Check the following dataset:
d = {'col1':[2,4,5,6],'col2':[8,8,6,1],'col3':[1,2,3,4],'col4':[4,4,4,4]}
df = pd.DataFrame(d,index=['Item1','Item2','Item1','Item2'])
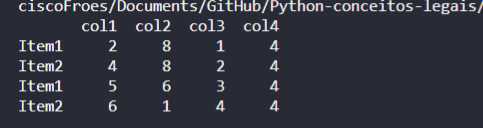
Lets say i want to interact through the columns, and create a diff column. That gives me difference beetween col1, col2 and them another diff column that gives me col3,col4. And so on like in a window by window style. Difference columns.
d = {'col1':[2,4,5,6],'col2':[8,8,6,1],'diff_1':[-6,-4,1,5],'col3':[1,2,3,4],'col4':[4,4,4,4],'diff_2':[-3,-2,-1,0]}
df = pd.DataFrame(d,index=['Item1','Item2','Item1','Item2'])
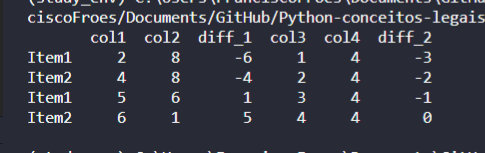
CodePudding user response:
You can check groupby then concat back
out = pd.concat([y.assign(**{'diff_{0}'.format(x 1): y.iloc[:,0] - y.iloc[:,1]})for x , y in df.groupby(np.arange(df.shape[1])//2,axis=1)],axis=1)
Out[166]:
col1 col2 diff_1 col3 col4 diff_2
Item1 2 8 -6 1 4 -3
Item2 4 8 -4 2 4 -2
Item1 5 6 -1 3 4 -1
Item2 6 1 5 4 4 0
CodePudding user response:
define a chunk function which iterate through a list
def chunk_list(lst, chunk_size):
for j in range(0, len(lst), chunk_size):
yield lst[j:j chunk_size]
then, use it as follows:
import pandas as pd
d = {'col1':[2,4,5,6],'col2':[8,8,6,1],'col3':[1,2,3,4],'col4':[4,4,4,4]}
df = pd.DataFrame(d,index=['Item1','Item2','Item1','Item2'])
for chunk in chunk_list(df.columns, 2):
diff = "diff" chunk[0] chunk[1]
df[diff] = df[chunk[0]] - df[chunk[1]]
CodePudding user response:
The idea below is, that you subtract all consecutive columns and then just pick the 2nd and the 4th diff columns:
# Use df.diff(axis=1) to subtract consecutive columns with each other. The multiply the result with -1
In [1575]: df_diff = df.diff(axis=1).mul(-1)[['col2', 'col4']].rename(columns={'col2': 'diff_1', 'col4': 'diff_2'})
# Concat the above result with the original dataframe
In [1577]: res = pd.concat([df, df_diff], axis=1)
In [1578]: res
Out[1578]:
col1 col2 col3 col4 diff_1 diff_2
Item1 2 8 1 4 -6 -3
Item2 4 8 2 4 -4 -2
Item1 5 6 3 4 -1 -1
Item2 6 1 4 4 5 0
Explanation:
In [1579]: df.diff(axis=1)
Out[1579]:
col1 col2 col3 col4
Item1 NaN 6 -7 3
Item2 NaN 4 -6 2
Item1 NaN 1 -3 1
Item2 NaN -5 3 0
The above result is basically like:
col1 = col1 - Nan # You don't need this
col2 = col2 - col1 # You need col1 - col2. So mul this by -1
col3 = col3 - col2 # You don't need this
col4 = col4 - col3 # You need col3 - col4. So mul this by -1
So below command produces the required diff columns.
df_diff = df.diff(axis=1).mul(-1)[['col2', 'col4']].rename(columns={'col2': 'diff_1', 'col4': 'diff_2'})