I'm working in a Python / Mesa environment and producing agent-based model output data which looks like the following:
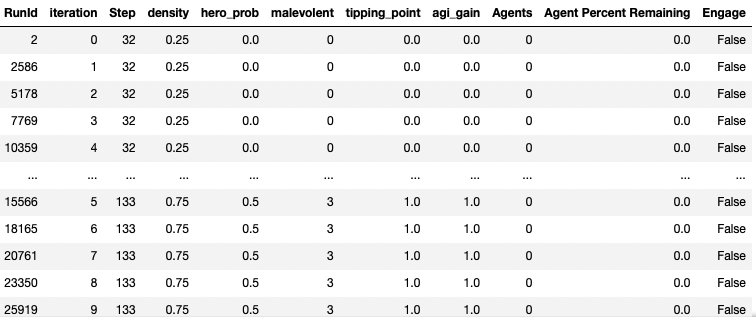
25920 rows by 11 columns. The df is sorted by the columns of which I've performed parametric runs producing all combinations of them: density, hero_prob, malevolent, tipping_point, agi_gain
The parameter space is 2592 and with 10 replications per combination...thus 25920 rows. What I am trying to do is create a new df for logistic regression which condenses every 10 rows of a given parameter combination with the most frequent entry for 'Engage' remains.
Thus, I'd end up a new 2592 x 11 df where the first row would be the same as the row with RunId value 2 above since all of those 'Engage' entries are False. A later parameter set with 7 True and 3 False would condense to a row with those parameter settings and True in the engage column for example. I tried the following code:
df_grouped = df_sorted.groupby(['density','hero_prob','malevolent','tipping_point','agi_gain'])['Engage'].agg(pd.Series.mode).to_frame()
But the results confuse me and I only have an Engage column, not the parameter settings. And agi_gain appears combined:
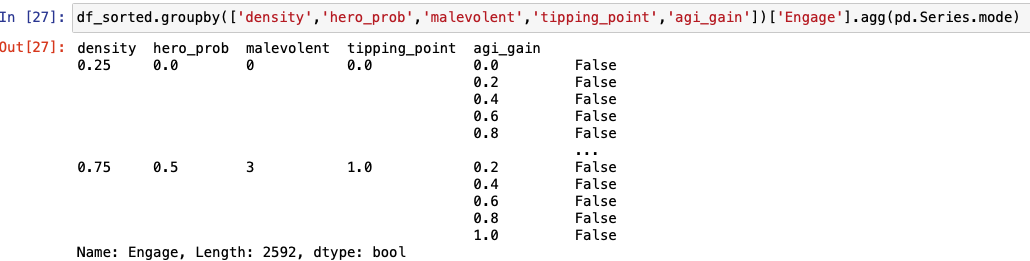 That structure isn't like my original df, which is what I'm trying to circle back to, but just condensed with the most common 'Engage' result.
That structure isn't like my original df, which is what I'm trying to circle back to, but just condensed with the most common 'Engage' result.
Bonus: In the event of 5 True, 5 False for a given parametric combination an "Engage" entry of "Tie" would be amazing. Thank you as always to this amazing community.
CodePudding user response:
Since parameters in the group are all the same, it is possible to just use mode:
df_sorted.groupby(parameter_columns).agg(pd.Series.mode)
For the tie support, an aggregation function would look something like:
def tie_mode(series):
counts = series.value_counts()
if len(counts) == 1: # a parameter column or all same results
return next(iter(series))
if counts.get(False) == counts.get(True):
return 'tie'
return counts.get(True, 0) > counts.get(False, 0)
df_sorted.groupby(parameter_columns).agg(my_agg)