We recently moved our database from MariaDB to AWS Amazon Aurora RDS (MySQL). We observed something strange in a set of queries. We have two queries that are very quick, but when together as nested subquery it takes ages to finish.
Here id is the primary key of the table
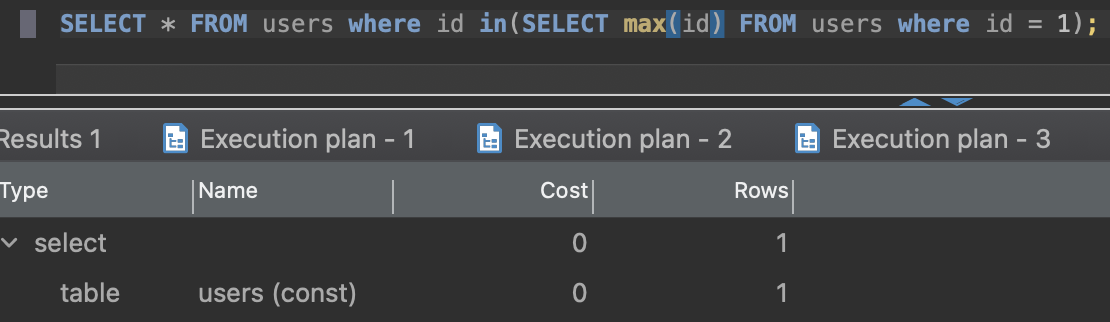
SELECT * FROM users where id in(SELECT max(id) FROM users where id = 1);
execution time is ~350ms
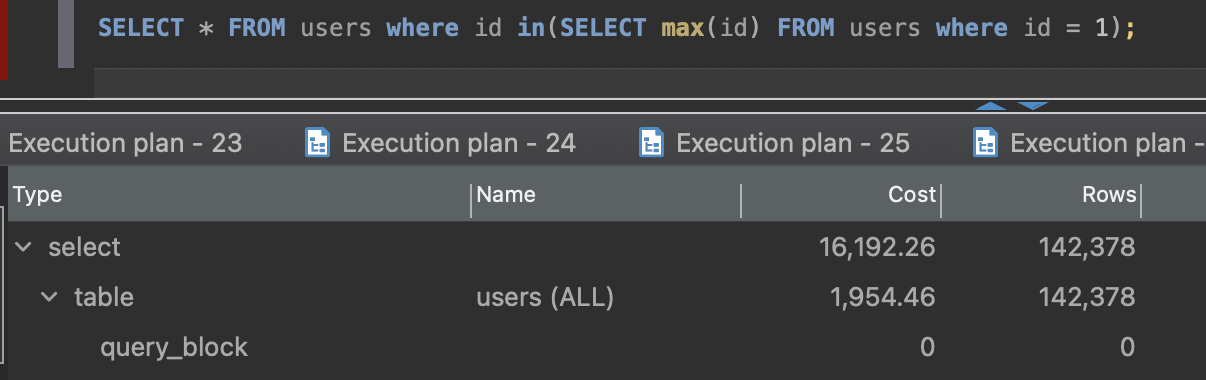
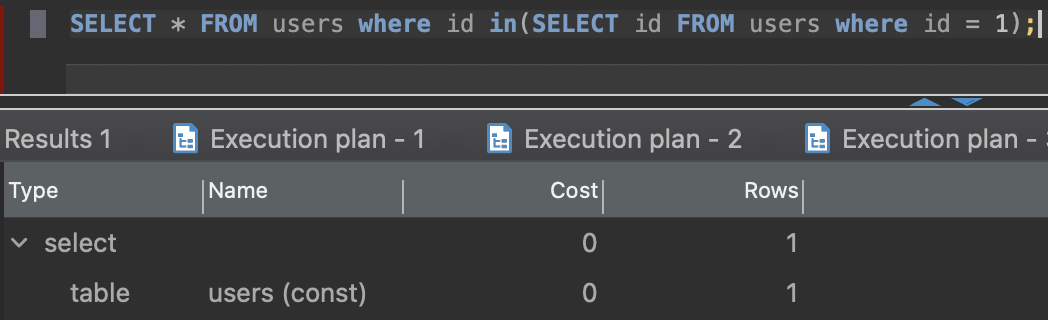
SELECT * FROM users where id in(SELECT id FROM users where id = 1);
execution time is ~130ms
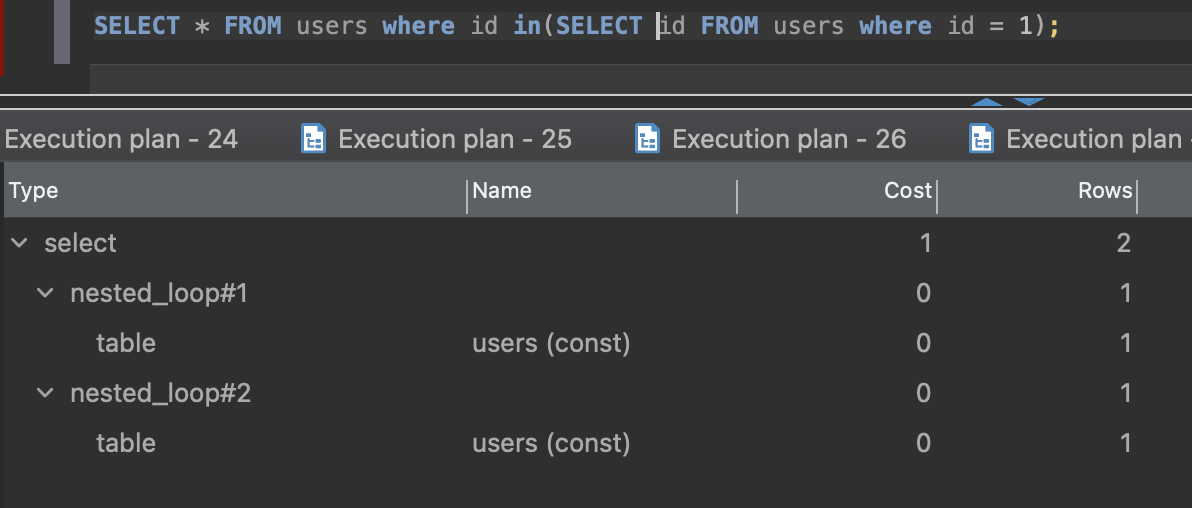
SELECT max(id) FROM users where id = 1;
execution time is ~130ms
SELECT id FROM users where id = 1;
execution time is ~130ms
We believe it has to do something with the type of value returned by max that is causing the indexing to be ignored when running the outer query from results of the sub query.
All the above queries are simplified for illustration of the problem. The original queries have more clauses as well as 100s of millions of rows. The issue did not exist prior to the migration and worked fine in MariaDB.
--- RESULTS FROM MariaDB ---
CodePudding user response:
MySQL seems to optimize less efficient compared to MariaDB (int this case).
When doing this in MySQL (see: DBFIDDLE1), the execution plans look like:
- For the query without
MAX:
| id select_type table partitions type | possible_keys | key key_len ref | rows | filtered Extra |
|---|---|---|---|---|
| 1 SIMPLE integers null const | PRIMARY | PRIMARY 4 const | 1 | 100.00 Using index |
| 1 SIMPLE integers null const | PRIMARY | PRIMARY 4 const | 1 | 100.00 Using index |
- For the query with
MAX:
| id select_type table partitions type | possible_keys | key key_len ref | rows | filtered Extra |
|---|---|---|---|---|
| 1 PRIMARY integers null index null | PRIMARY | 4 null | 1000 | 100.00 Using where; Using index |
| 2 DEPENDENT SUBQUERY null null null null | null | null null | null | null Select tables optimized away |
While MariaDB (see: DBFIDDLE2 does have a better looking plan when using MAX:
| id select_type table type | possible_keys | key key_len ref | rows | filtered Extra |
|---|---|---|---|---|
| 1 PRIMARY system null | null | null null | 1 | 100.00 |
| 1 PRIMARY integers const PRIMARY | PRIMARY | 4 const | 1 | 100.00 Using index |
| 2 MATERIALIZED null null null | null | null null | null | null Select tables optimized away |
EDIT: Because of time (some lack of it