Hi I am trying to get "True" as output if there is a repeated element in a dataframe, and "False" if there is no repeated element. This should not take the empty cells into account.
Example 1:
import pandas as pd
data_df = {'col1': ['A','B', 'C', 'D'],
'col2': ['E','F', '', 'G'],
'col3': ['H', '', ' ', ' ']}
df = pd.DataFrame(data_df)
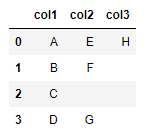
Should display "False"
Example 2:
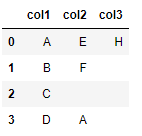
Should display "True"
Example3:
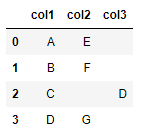
Should display "True"
CodePudding user response:
You can use:
out = (df.stack() # stack to Series, removing NaNs
# remove empty/space strings
.loc[lambda s: s.str.strip().ne('')]
# is there any duplicate?
.duplicated().any()
)
Outputs:
False
True
True