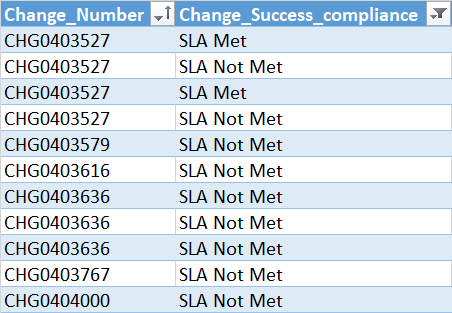
I want to drop duplicate records in the above dataframe based on the condition that if there are multiple records with the same "Change_Number" but in one record SLA is met ("SLA Met") then drop all other records and keep this one and if there is no "SLA Met" in duplicate records then keep the first appearance of "SLA Not Met" and drop others.
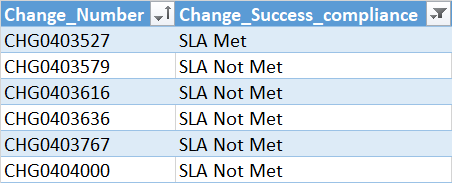
expected output:
CodePudding user response:
So here I believe it is more a matter of grouping & filtering.
Here's my proposed solution:
def filter_sla_met(group):
condition_met = group["change_success_compliance"] == "SLA Met"
if condition_met.any():
# True if the group (change number) contains at least one "SLA Met".
# Filters those rows where the condition is met.
# Keeps only the first row (index 0).
group_result = group.loc[condition_met].iloc[[0]]
else:
# False if the group does not have any "SLA Met".
# Keeps all the rows.
group_result = group
return group_result
# Use .reset_index to remove the extra index layer created by Pandas,
# which is not necessary in this situation.
groups = df.groupby(["change_number"], as_index=False)
results = groups.apply(filter_sla_met).reset_index(level=0, drop=True)
print(results)
I hope this helps.
CodePudding user response:
use:
df['id']=df.groupby('Change_Success_compliance').ngroup() #define an id for every status
df=df.groupby(['Change_Number']).agg({'id':'min'}).reset_index()
df["id"]=df["id"].replace({0:'SLA Met',1:'SLA Not Met'}) #replace ids