I have a table named "table1" and I'm splitting it based on a criterion, and then joining the split parts one by one in for loop. The following is a representation of what I am trying to do.
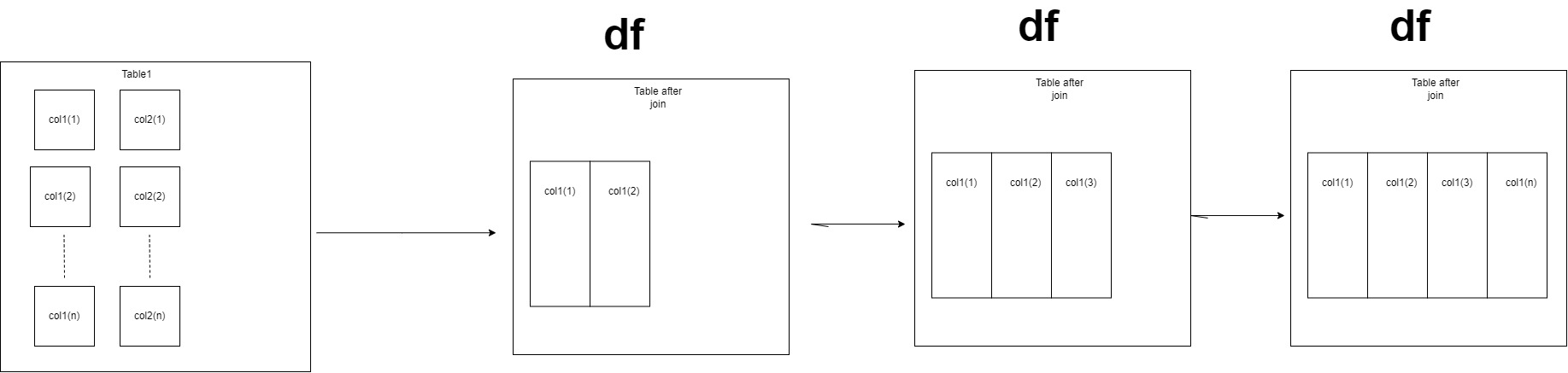
When I joined them, the joining time increased exponentially.
0.7423694133758545
join
0.4046192169189453
join
0.5775985717773438
join
5.664674758911133
join
1.0985417366027832
join
2.2664384841918945
join
3.833379030227661
join
12.762675762176514
join
44.14520192146301
join
124.86295890808105
join
389.46189188957214
. Following are my parameters
spark = SparkSession.builder.appName("xyz").getOrCreate()
sqlContext = HiveContext(spark)
sqlContext.setConf("spark.sql.join.preferSortMergeJoin", "true")
sqlContext.setConf("spark.serializer","org.apache.spark.serializer.KryoSerializer")
sqlContext.setConf("spark.sql.shuffle.partitions", "48")
and
--executor-memory 16G --num-executors 8 --executor-cores 8 --driver-memory 32G
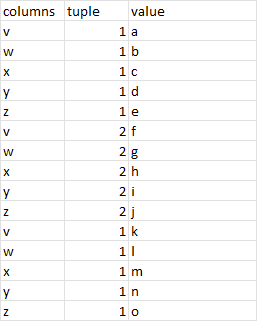
Source table
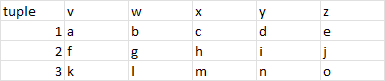
Desired output table
In the join iteration, I also increased the partitions to 2000 and decreased it to 4, and cached the DF data frame by df.cached(), but nothing worked. I know I am doing something terribly wrong but I don't know what. Please can you guide me on how to correct this.
I would really appreciate any help :)
code:
df = spark.createDataFrame([], schema=SCHEMA)
for i, column in enumerate(columns):
df.cache()
df_part = df_to_transpose.where(col('key') == column)
df_part = df_part.withColumnRenamed("value", column)
if (df_part.count() != 0 and df.count() != 0):
df = df_part.join(broadcast(df), 'tuple')
CodePudding user response:
I had same problem a while ago. if you check your pyspark web ui and go in stages section and checkout dag visualization of your task you can see the dag is growing exponentialy and the waiting time you see is for making this dag not doing the task acutally. I dont know why but it seams when you join table made of a dataframe with it self pyspark cant handle partitions and it's getting a lot bigger. how ever the solution i found at that moment was to save each of join results on seperated files and at the end after restarting the kernel load and join all the files again. It seams if dataframes you want to join are not made from each other you dont see this problem.
CodePudding user response:
Add a checkpoint every loop, or every so many loops, so as to break lineage.