What am I trying to do
I have 3 tables which are being joined to create a desired output.
Table 1 (800K records) : This is a partitioned hive external table by date (parquet file structure ). The schema is deeply nested. Following is a portion of the schema
root
| - uuid
| - data
| - k1 - string
| - k2 - string
| - ...
| ….
| - dt - string (partition column)
Table 2 (0.5 million records) /Table 3 (31K records) : metadata tables
root
| - insert_date
| - k_sub
| - action_date
| ….
SQL being executed (Generated by a internal library)
SELECT input_file_name() as filename, uuid, data.k1, data.k2, dt
FROM table_1
WHERE NOT EXISTS(SELECT 1 FROM table_2 WHERE (k_sub = data.k1) AND dt > action_date)
AND EXISTS(
SELECT 1 FROM table_3 WHERE (k_sub = data.k1) AND (dt < action_date OR dt < DATE_ADD(CURRENT_DATE(), -1460))
Spark settings
Num of executors = 50
Executor memory = 10g
Driver memory = 10g
The query runs very slow runs for 1.1 hrs and fails. Looking into the sparkUI (SQL table).
I increased the num of executors to 100 and the job completed but I'm not confident. The plan looks like this
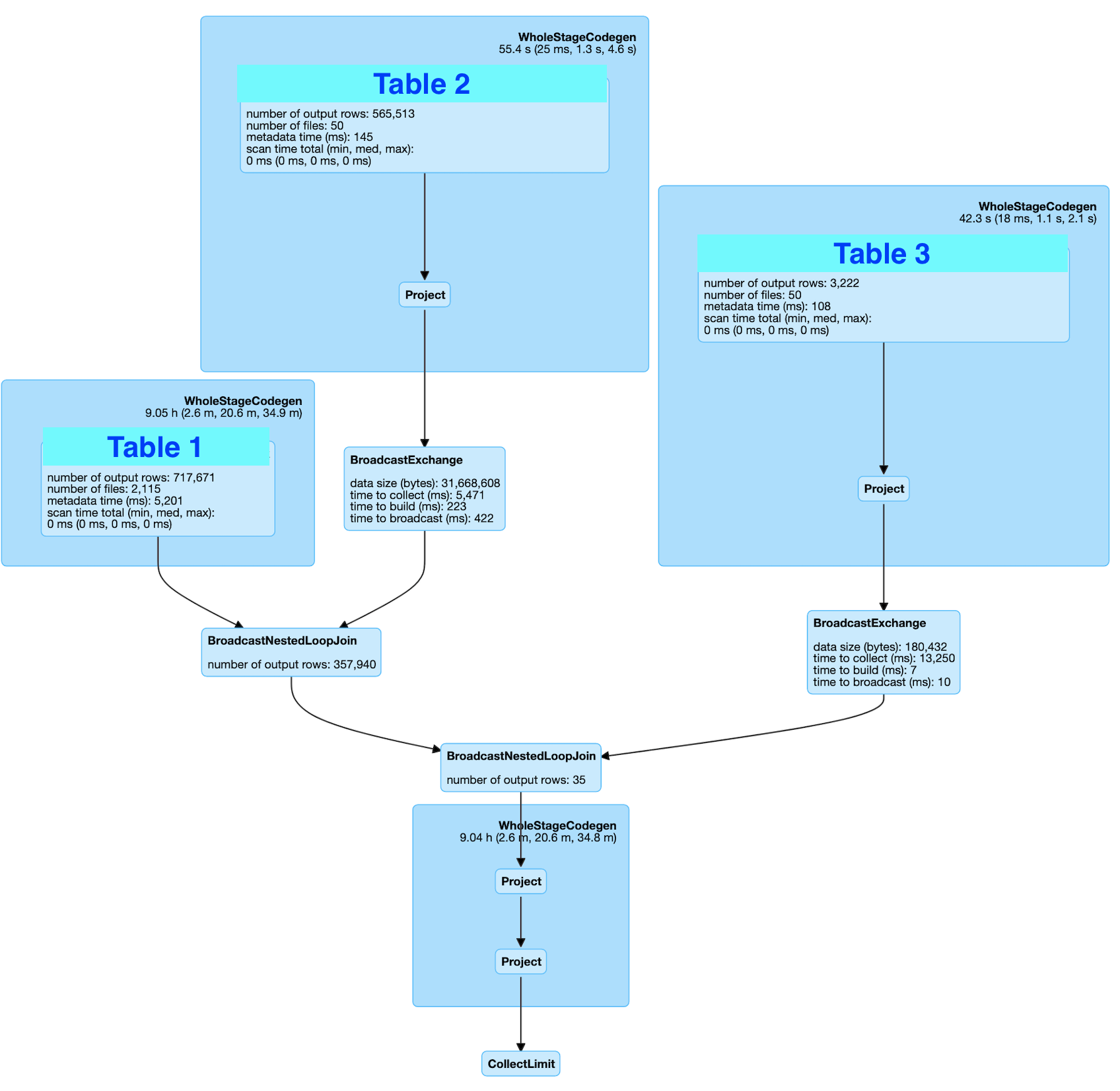
Based on my research, BroadcastNestedLoopJoin is not good to have. As it is SQL, I tried adding /* BroadcastJoin */ hint but still did not help. Anyone has thoughts of how I could approach this problem and improve the performance?
CodePudding user response:
I faced the same problem before, i had a table with billion records and 3 more (with hundred thousand rows) tables to enrich my table. I was combining them and doing aggregation. it was accelerated when I added the following configurations. but now I don't remember exactly which config I accelerated it with. It's been a long time since. I hope it works for you...
I have given these additionally when creating spark session ;
.config("hive.exec.dynamic.partition.mode", "nonstrict") \
.config("hive.exec.dynamic.partition", "true") \
.config("hive.metastore.try.direct.sql", "true") \
.config("hive.merge.smallfiles.avgsize", "40000000") \
.config("hive.merge.size.per.task", "209715200") \
.config("hive.exec.parallel", "true") \
.config("spark.debug.maxToStringFields", "5000") \
.config("spark.yarn.executor.memoryOverhead","22g") \
.config("dfs.blocksize", "268435456") \
.config("spark.kryoserializer.buffer.max", "2000m") \
.config("spark.sql.adaptive.enabled", "true") \
.config("spark.sql.shuffle.partitions","3200") \
.config("spark.default.parallelism","3200") \
After creating the session, I set the following configurations. Especially after adding autoBroadcastJoinThreshold below i saw it speed up;
from pyspark.sql import HiveContext
c = HiveContext(spark)
c.setConf('spark.sql.parquet.compression.codec', 'gzip')
c.setConf('spark.sql.autoBroadcastJoinThreshold', 1000 * 1024 * 1024)
c.setConf('spark.sql.broadcastTimeout', '36000')
c.setConf("spark.sql.adaptive.skewJoin.enabled","true")
CodePudding user response:
Based on my research, BroadcastNestedLoopJoin is not good to have. As it is SQL, I tried adding /* BroadcastJoin */ hint but still did not help. Anyone has thoughts of how I could approach this problem and improve the performance?
Looks like those not exists are translated into non-equi join (because they are using checking range on the condition) and in this case Spark cannot use hash join or sort-merge join. Thats also the reason why your broadcast hint is not forcing spark to use broadcastHashJoin (its only for equi join)
You can find more details in this comment in source code Spark source code
// If it is an equi-join, we first look at the join hints w.r.t. the following order:
// 1. broadcast hint: pick broadcast hash join if the join type is supported. If both sides
// have the broadcast hints, choose the smaller side (based on stats) to broadcast.
// 2. sort merge hint: pick sort merge join if join keys are sortable.
// 3. shuffle hash hint: We pick shuffle hash join if the join type is supported. If both
// sides have the shuffle hash hints, choose the smaller side (based on stats) as the
// build side.
// 4. shuffle replicate NL hint: pick cartesian product if join type is inner like.
//
// If there is no hint or the hints are not applicable, we follow these rules one by one:
// 1. Pick broadcast hash join if one side is small enough to broadcast, and the join type
// is supported. If both sides are small, choose the smaller side (based on stats)
// to broadcast.
// 2. Pick shuffle hash join if one side is small enough to build local hash map, and is
// much smaller than the other side, and `spark.sql.join.preferSortMergeJoin` is false.
// 3. Pick sort merge join if the join keys are sortable.
// 4. Pick cartesian product if join type is inner like.
// 5. Pick broadcast nested loop join as the final solution. It may OOM but we don't have
// other choice.
If you cant change your condition i am afraid that you can only try to adjust your resources to make it stable and live with it