I am running a code to try to extract the length of each file in a directory.
I cannot figure out why I am getting error : KeyError: "There is no item named 'Test1' in the archive"
Code:
from io import BytesIO
from pathlib import Path
from zipfile import ZipFile
import pandas as pd
def process_files(files: list) -> pd.DataFrame:
file_mapping = {}
for file in files:
data_mapping = pd.read_excel(BytesIO(ZipFile(file).read(Path(file).stem)), sheet_name=None)
row_counts = []
for sheet in list(data_mapping.keys()):
row_counts.append(len(data_mapping.get(sheet)))
file_mapping.update({file: sum(row_counts)})
frame = pd.DataFrame([file_mapping]).transpose().reset_index()
frame.columns = ["file_name", "row_counts"]
return frame
path = r'//Stack/Over/Flow/testfiles/'
zip_files = (str(x) for x in Path(path).glob("*.zip"))
df = process_files(zip_files)
print(df)
my files:

inside test1 zip:
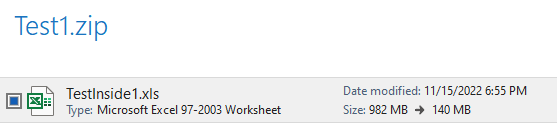
any help would be appreicated.
Edit - How would I apply the code to the zip files in subdirectories like so? So within 2022 - 05 there would be zip files, and within 2022-06 there would be zip files, etc.
CodePudding user response:
For each file in your archive, you call this line:
ZipFile(file).read(Path(file).stem)
This means that within each zipfile given by file, you must have a file within the archive with the same name, but without the extension (i.e., the stem).
So for this to work, you'd need to have a structure like this:
test1.zip
test1
test2.zip
test2
Instead, you have the file TestInside1.xls - very different from the filename test1. You have a number of options for constructing valid paths for file names inside the zip archive - for one, you could use ZipFile.namelist.
For example, you could replace this:
data_mapping = pd.read_excel(BytesIO(ZipFile(file).read(Path(file).stem)), sheet_name=None)
with this:
archive = ZipFile(file)
# find file names in the archive which end in `.xls`, `.xlsx`, `.xlsb`, ...
files_in_archive = archive.namelist()
excel_files_in_archive = [
f for f in files_in_archive if Path(f).suffix[:4] == ".xls"
]
# ensure we only have one file (otherwise, loop or choose one somehow)
assert len(excel_files_in_archive) == 1
# read in data
data_mapping = pd.read_excel(
BytesIO(archive.read(excel_files_in_archive[0])),
sheet_name=None,
)