I have a dataframe bmi. I can summarize it like this:
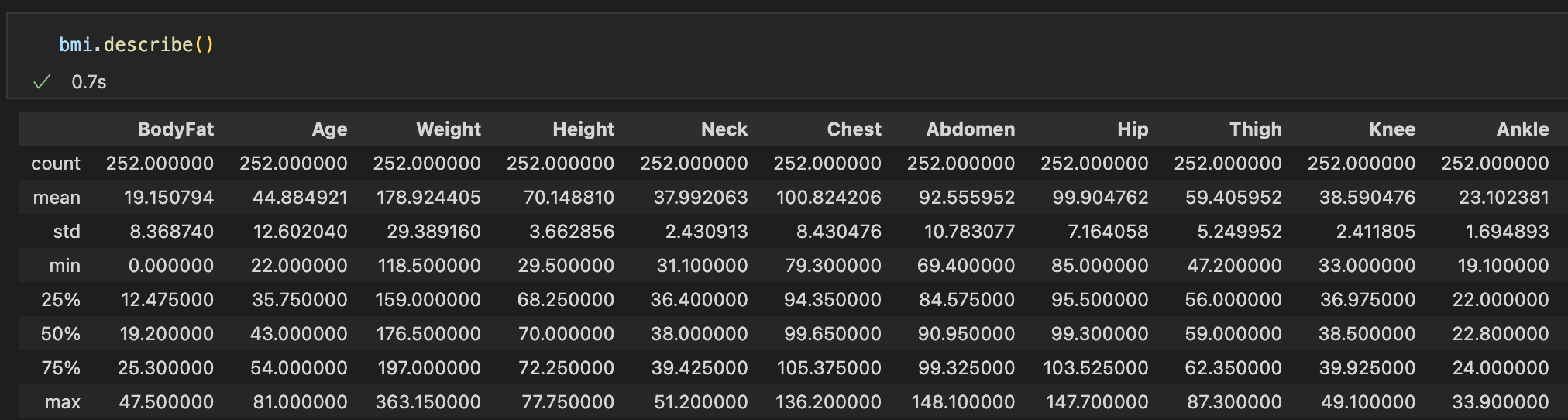
Now I want to summarize the dataframe based on Age values measured in decades. So I do the following:
bmi.groupby(by=bmi.Age//10).describe().stack()
which shows me the following summary:
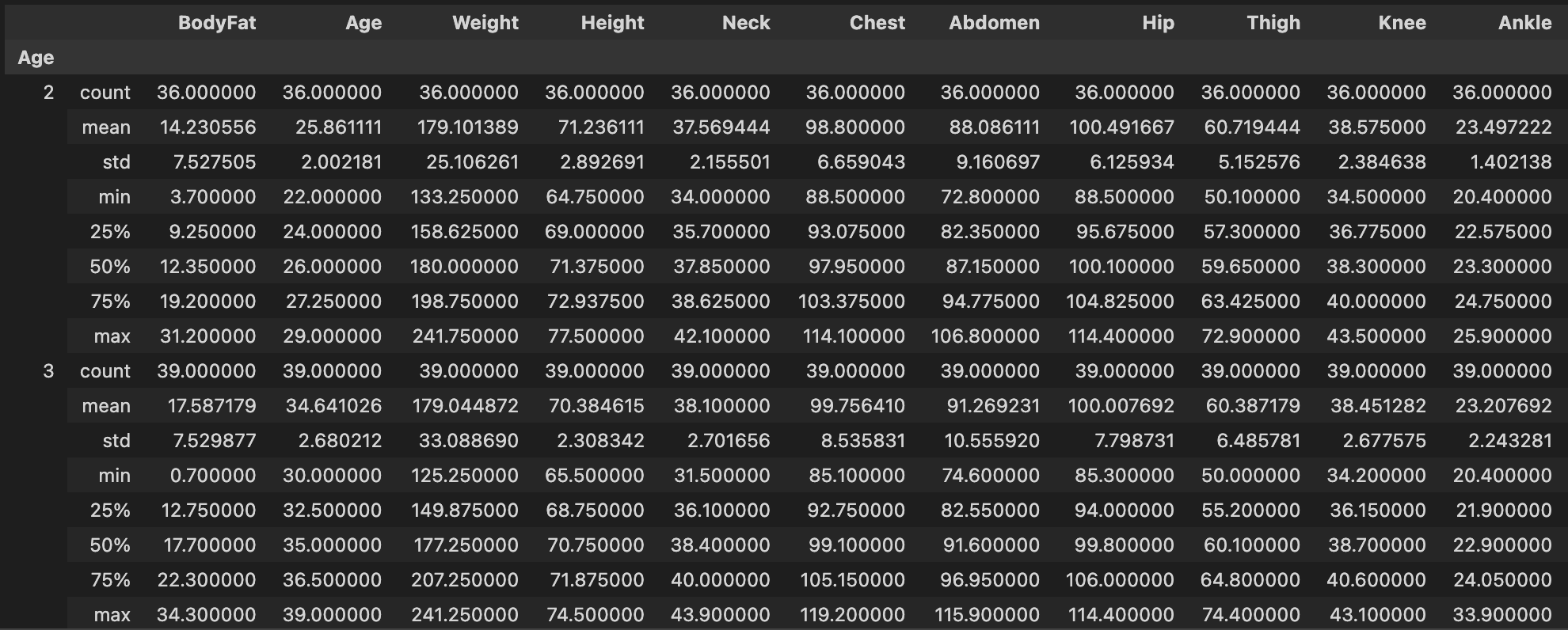
Note that this creates an index named Age which I'd rather name Decade.
How can I rename the name of this index (to be precise, index level) during the generation of the dataframe?
So I am looking for a function which_func() so that my code can read like this:
bmi.groupby(by=bmi.Age//10).describe().which_func({'Age':'Decade'}).stack()
and I get the output:
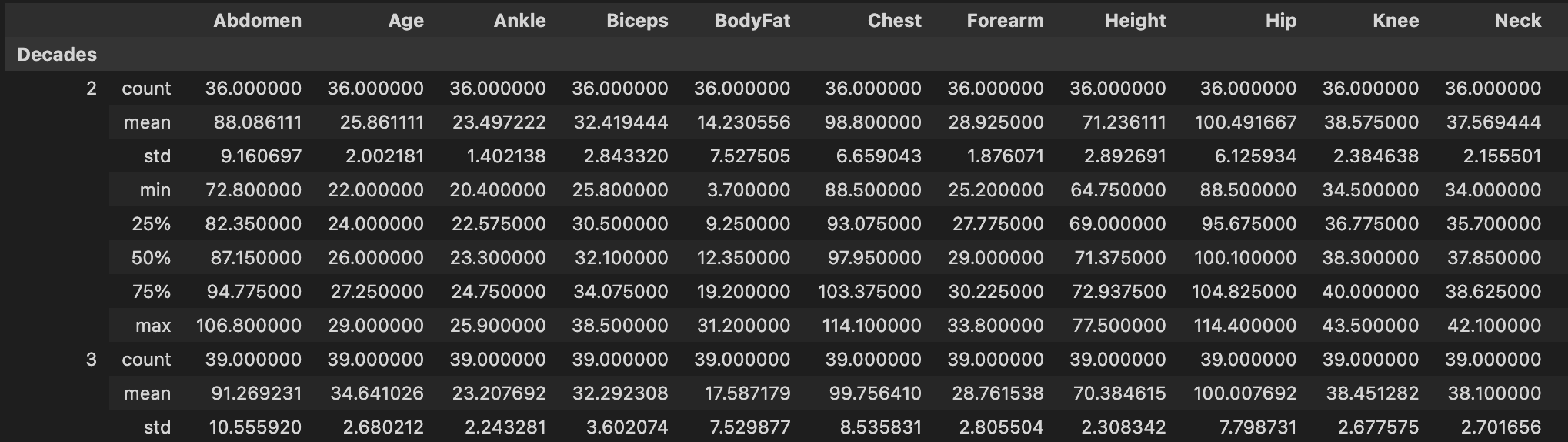
The shortest single-line version I can come up with is:
bmi.groupby(by=bmi.Age//10).describe().reset_index(level='Age', names='Decades').set_index('Decades').stack()
which seems redundant.
The built-in method DataFrame.rename() renames the labels of an index, not its name, and other methods require extracting the index or their names and then renaming, overwriting them so the code cannot be chained.
Given that this is a very common situation in groupby()-aggregate() setup, is there really no way to do this with chained code?
CodePudding user response:
What you are looking for is rename_axis():
>>> bmi.groupby(by=bmi.Age//10).describe().rename_axis(index={'Age': 'Decade'}).stack()
Bodyfat Age Weight
Decade
1.0 count 9.000000 9.000000 9.000000
mean 30.779899 16.981942 32.795294
std 4.341956 1.415877 5.292009
min 24.080597 14.769285 24.887466
25% 27.655679 16.137036 30.101671
... ... ... ...
4.0 min 27.594864 41.519583 24.699921
25% 27.594864 41.519583 24.699921
50% 27.594864 41.519583 24.699921
75% 27.594864 41.519583 24.699921
max 27.594864 41.519583 24.699921
For the actual result above, we used the following reproducible example:
# minimal example
import numpy as np # only needed to create the example frame
np.random.seed(0)
bmi = pd.DataFrame(np.random.normal(30, 5, size=(250, 3)),
columns='Bodyfat Age Weight'.split())
The following forms are all equivalent:
bmi.groupby(by=bmi.Age//10).describe().rename_axis(index='Decade').stack()
bmi.groupby(by=bmi.Age//10).describe().rename_axis('Decade', axis=0).stack()
bmi.groupby(by=bmi.Age//10).describe().stack().rename_axis(index={'Age': 'Decade'})
(the last one shows that rename_axis() can be called after .stack(), meaning it can be used on a MultiIndex as well).
You can of course also derive a new variable Decade before groupby:
>>> bmi.assign(Decade=bmi['Age']//10).groupby('Decade').describe().stack()
Bodyfat Age Weight
Decade
1.0 count 9.000000 9.000000 9.000000
mean 30.779899 16.981942 32.795294
std 4.341956 1.415877 5.292009
min 24.080597 14.769285 24.887466
25% 27.655679 16.137036 30.101671
... ... ... ...
4.0 min 27.594864 41.519583 24.699921
25% 27.594864 41.519583 24.699921
50% 27.594864 41.519583 24.699921
75% 27.594864 41.519583 24.699921
max 27.594864 41.519583 24.699921