I have a spreadsheet where columns "A", "B" and "C" have data, I need to save the webscraping data in column "D".
Currently, it deletes the contents of all columns and saves the information in column "B", this is my problem, as it should save in column "D" and keep the data from the other columns
I tried the command below and I had no success, because it just created a column named "c". pd.DataFrame(data, columns=["c"])
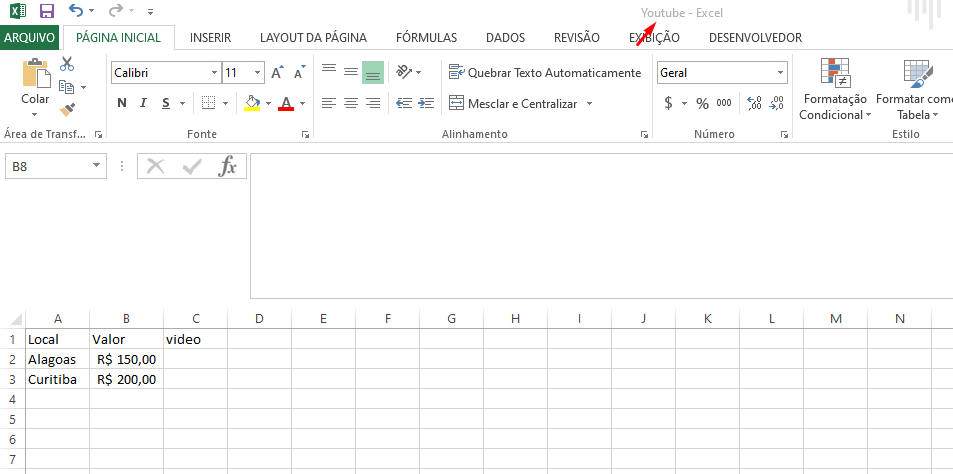
just below the command I use to save all my webscraping data
data = {'Video': links}
df = pd.DataFrame(data)
df.to_excel(r"C:\__Imagens e Planilhas Python\Facebook\Youtube.xlsx", engine='xlsxwriter')
print(df)
CodePudding user response:
You should have included what the data in "Youtube.xlsx" and data look like. The answer below is suggested with the assumption that they're the same length and that "Youtube.xlsx" has no index column and exactly 3 columns so any added column will be the 4th by default.
I don't know what's in "Youtube.xlsx" or in data, but the way it's coded df will have only one column (Video), and .to_excel uses write mode by default, so
Currently, it deletes the contents of all columns and saves the information in column "B"
[I expect it uses column the first column as index, so Video ends up as the second column.] If you don't want to write over the previous contents, the usual approach is to append with mode='a'; but that will append rows, and [afaik] there is no way to append columns directly to a file.
You could read the file into a DataFrame, then add the column and save.
filepath = r"C:\__Imagens e Planilhas Python\Facebook\Youtube.xlsx"
df = df.read_excel(filepath) #, header=None) # if there is no header row
df['Video'] = links
df.to_excel(filepath, engine='xlsxwriter') #, index=False)
[Use a different column name if the file already had a Video column that you want to preserve.]