Recently i was working with python beautiful soup to extract some data and put it into pandas DataFrame. I used python beautiful soup to extract some of the hotel data from the website booking.com. I was able to extract some of the attributes very correctly without any empty. Here is my code snippet:
def get_Hotel_Facilities(soup):
try:
title = soup.find_all("div", attrs={"class":"db29ecfbe2 c21a2f2d97 fe87d598e8"})
new_list = []
# Inner NavigatableString Object
for i in range(len(title)):
new_list.append(title[i].text.strip())
except AttributeError:
new_list=""
return new_list
The above code is my function to retrieve the Facilities of a hotel and return the facilitites List items.
page_no=0
d = {"Hotel_Name":[], "Hotel_Rating":[], "Room_type":[],"Room_price":[],"Room_sqft":[],"Facilities":[],"Location":[]}
while (page_no<=25):
URL = f"https://www.booking.com/searchresults.html?aid=304142&label=gen173rf-1FCAEoggI46AdIM1gDaGyIAQGYATG4ARfIAQzYAQHoAQH4AQKIAgGiAg1wcm9qZWN0cHJvLmlvqAIDuAKwwPadBsACAdICJDU0NThkNDAzLTM1OTMtNDRmOC1iZWQ0LTdhOTNjOTJmOWJlONgCBeACAQ&sid=2214b1422694e7b065e28995af4e22d9&sb=1&sb_lp=1&src=theme_landing_index&src_elem=sb&error_url=https://www.booking.com/hotel/index.html?aid=304142&label=gen173rf1FCAEoggI46AdIM1gDaGyIAQGYATG4ARfIAQzYAQHoAQH4AQKIAgGiAg1wcm9qZWN0cHJvLmlvqAIDuAKwwPadBsACAdICJDU0NThkNDAzLTM1OTMtNDRmOC1iZWQ0LTdhOTNjOTJmOWJlONgCBeACAQ&sid=2214b1422694e7b065e28995af4e22d9&&ss=goa&is_ski_area=0&checkin_year=2023&checkin_month=1&checkin_monthday=13&checkout_year=2023&checkout_month=1&checkout_monthday=14&group_adults=2&group_children=0&no_rooms=1&b_h4u_keep_filters=&from_sf=1&offset{page_no}"
new_webpage = requests.get(URL, headers=HEADERS)
soup = BeautifulSoup(new_webpage.content,"html.parser")
links = soup.find_all("a", attrs={"class":"e13098a59f"})
for link in links:
new_webpage = requests.get(link.get('href'), headers=HEADERS)
new_soup = BeautifulSoup(new_webpage.content, "html.parser")
d["Hotel_Name"].append(get_Hotel_Name(new_soup))
d["Hotel_Rating"].append(get_Hotel_Rating(new_soup))
d["Room_type"].append(get_Room_type(new_soup))
d["Room_price"].append(get_Price(new_soup))
d["Room_sqft"].append(get_Room_Sqft(new_soup))
d["Facilities"].append(get_Hotel_Facilities(new_soup))
d["Location"].append(get_Hotel_Location(new_soup))
page_no = 25
The above code is the main one where the while loop will traverse the linked pages and retrieve the URL's of the pages. After retrieving ,it goes to every page to retrieve the corresponding atrributes.
I was able to retrieve the rest of the attributes correctly but i am not able to retrive the facilities, Like only some of the room facilities are being returned and some are not returning.
Here is my below o/p after making it into a pandas data frame.
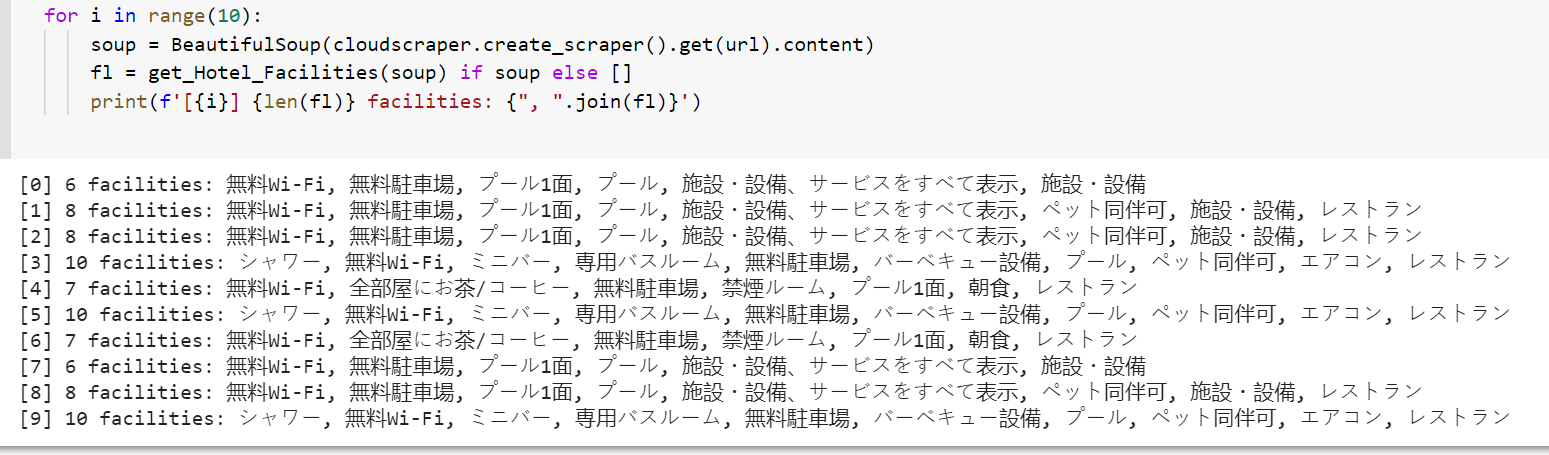
(But the inconsistencies might be due to using cloudscraper - maybe you'll get better results with your headers?)