Background
Here's an R dataframe d:
d <- data.frame(ID = c("a","a","a","a","a","a","b","b"),
event = c("G12","R2","O99","B4","B4","A24","L5","J15"),
stringsAsFactors=FALSE)
It looks like so:
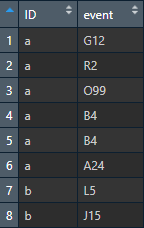
You see 2 people represented by ID, each with >1 event. ID=a has 6 events but only 5 distinct ones, while ID=b has 2 events, both distinct.
The Problem
I'd like to calculate the average number of distinct / unique events per person in d. In this case, the arithmetic goes like this:
(5 unique events 2 unique events) / 2 distinct ID's = 3.5 unique events per person, which is the answer I'm looking for.
What I've tried
I've attempted something like this so far:
d %>%
group_by(ID) %>%
summarise(mean = mean(tally(unique(event))))
But this throws an error.
CodePudding user response:
n_distinct would give you count of distinct events, you can calculate that per ID and then calculate the ratio.
library(dplyr)
d %>%
group_by(ID) %>%
summarise(distinct_event = n_distinct(event)) %>%
summarise(ratio = mean(distinct_event))
# ratio
# <dbl>
#1 3.5
CodePudding user response:
data.table
library(data.table)
library(magrittr)
df <- data.frame(ID = c("a","a","a","a","a","a","b","b"),
event = c("G12","R2","O99","B4","B4","A24","L5","J15"),
stringsAsFactors=FALSE)
setDT(df)[, list(uniqueN(event)), by = ID] %>%
.[, list(ratio = mean(V1))]
#> ratio
#> 1: 3.5
Created on 2021-10-01 by the reprex package (v2.0.1)