I am trying to extract the element that are circled in red in the picture below from this website:
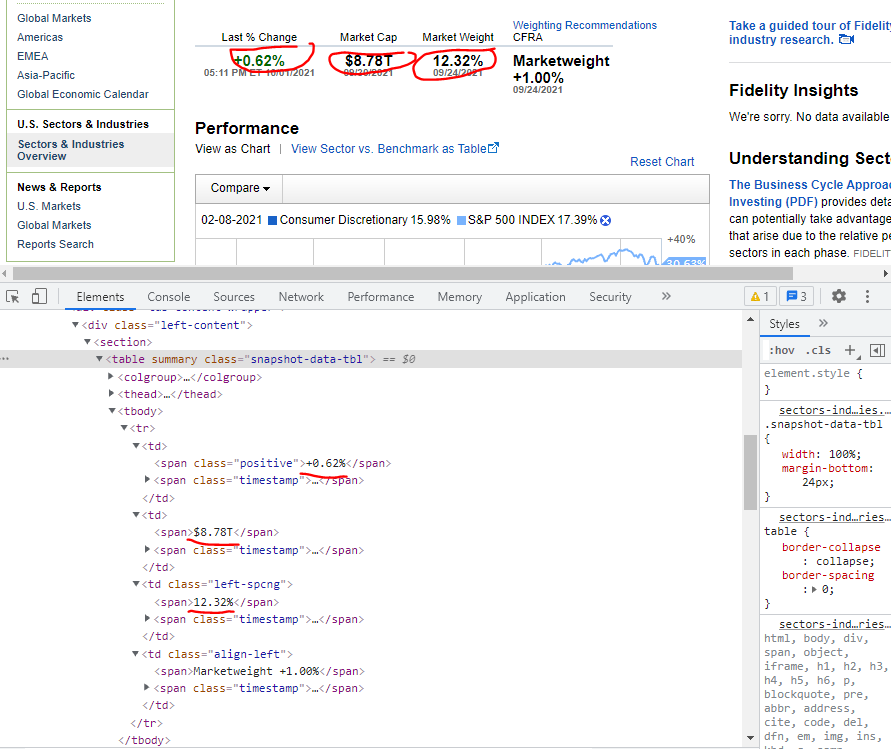
However, it keeps giving me this error "ResultSet object has no attribute 'find'. You're probably treating a list of elements like a single element. Did you call find_all() when you meant to call find()?"
My idea is to narrow down the search to the "td" tag and use find to get the element from the "span" tag, but I just can't get it to work. I tried using both find() and find_all() but both keep giving me this error, below is my code:
from bs4 import BeautifulSoup
url = "https://eresearch.fidelity.com/eresearch/markets_sectors/sectors/sectors_in_market.jhtml?
tab=learn§or=25"
response = requests.get(url)
soup = BeautifulSoup(response.content,'lxml')
b = soup.select('div.left-content table.snapshot-data-tbl tr td')
print(b.find("span", class_='positive').text)
Can I please get some help on this? Thanks!
CodePudding user response:
soup.select returns a container with the matches from the provided CSS selector. The soup.find method can only be applied to an element node from the page source, not the set of results from soup.select. Instead, you can iterate over the results of soup.select to get the text from the target spans:
r = [i.get_text(strip=True) for i in soup.select('div.left-content table.snapshot-data-tbl tr td > span:nth-of-type(1)')[:3]]
Output:
[' 0.62%', '$8.82T', '12.32%']
CodePudding user response:
Typically it's cleaner to find the element by class or id if possible over the longer CSS selector. In this case the data you want is inside the table with class="snapshot-data-tbl" within the first 3 td elements.
Here's another solution to extract the values:
from bs4 import BeautifulSoup
import requests
url = "https://eresearch.fidelity.com/eresearch/markets_sectors/sectors/sectors_in_market.jhtml?tab=learn§or=25"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
table = soup.find('table', class_="snapshot-data-tbl")
r = [td.find('span').text for td in table.find_all('td')[:3]]
print(r)
Output:
[' 0.62%', '$8.82T', '12.32%']