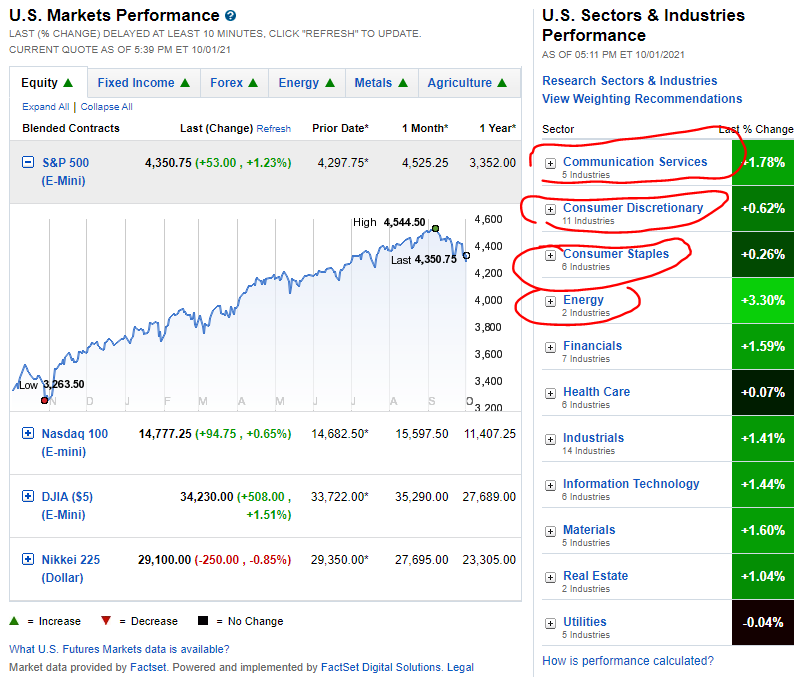
I am new to web scraping and a bit confused with my current situation. Is there a way to extract the link for all the sector from this website(where I circled in red) From the html inspector, it seems like it is under the "performance-section" class and it is also under the "heading" class. My idea was to start from the "performance-section" then reach the "a" tag href in the end to get the link.
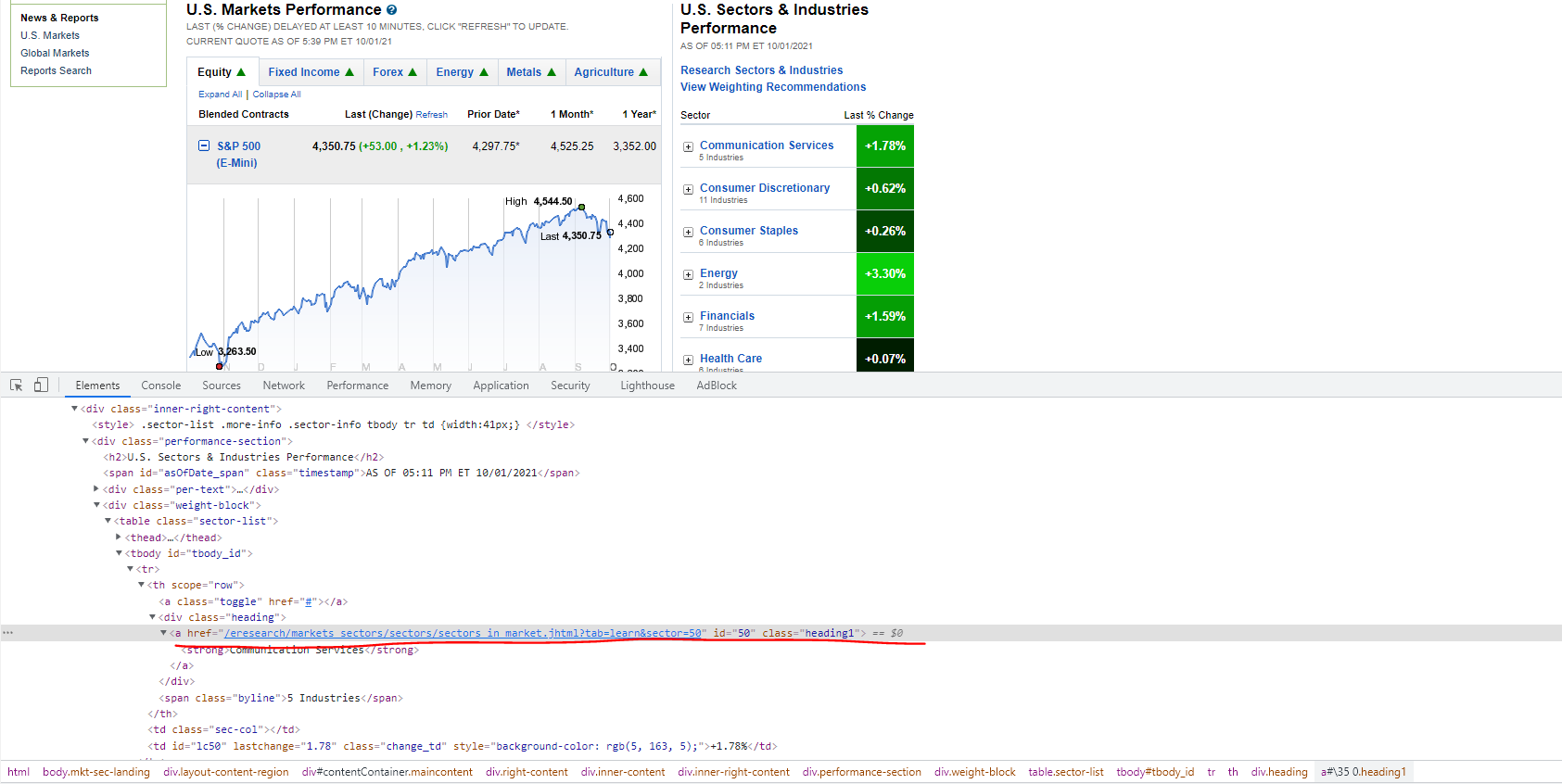
I tried to use the following code but it is giving me "None" as a result. I stopped here because if I am already getting None before getting the "a" tag, then I think there is no point of keep going.
import requests
import urllib.request
from bs4 import BeautifulSoup
url = "https://eresearch.fidelity.com/eresearch/goto/markets_sectors/landing.jhtml"
response = requests.get(url)
results_page = BeautifulSoup(response.content,'lxml')
heading =results_page.find('performance-section',{'class':"heading"})
Thanks in advance!
CodePudding user response:
You are on the right track with your mind game.
Problem
You should take another look at the documentation, because currently you don't even try to select tags, but try a mix of classes - It is also possible, but to learn you should start step by step.
Solution to get the <a> and its href
This will select all <a> in <div> with class heading
that parents are <div> with class performance-section
soup.select('div.performance-section div.heading a')
.
import requests
from bs4 import BeautifulSoup
url = "https://eresearch.fidelity.com/eresearch/goto/markets_sectors/landing.jhtml"
response = requests.get(url)
soup = BeautifulSoup(response.content,'lxml')
[link['href'] for link in soup.select('div.performance-section div.heading a')]