| k4nllk |
Update: Whassup bro? |
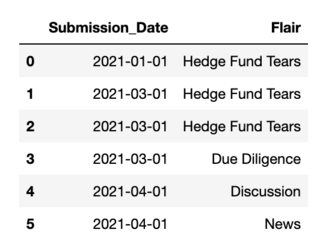
And here is a sample implementation:
unique_flairs = list(df['Flair'].unique())
flair_df = pd.DataFrame()
for date in df['Submission_Date'].unique():
date_subset = df.loc[df['Submission_Date'] == date]
counts = date_subset['Flair'].value_counts()
shares = counts / len(date_subset)
shares_df = pd.DataFrame(shares).transpose()
shares_df['Submission_Date'] = date
for flair in [x for x in unique_flairs if x not in shares_df.columns]:
shares_df[flair] = np.nan
flair_df = pd.concat([flair_df, shares_df])
flair_df = flair_df.reset_index(drop=True)
flair_df = flair_df[['Submission_Date'] unique_flairs]
display(flair_df)
Output:
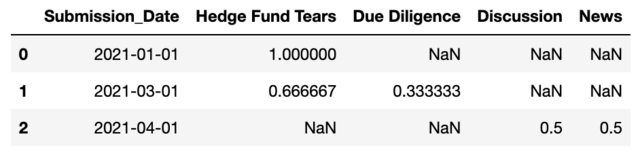
CodePudding user response:
You can use pivot table to achieve this result. I made up the input data frame with some random values.
data = pandas.DataFrame.from_dict({
"Submission_Date": [
datetime.date(2021, 1, 1),
datetime.date(2021, 1, 1),
datetime.date(2021, 1, 2),
datetime.date(2021, 1, 2),
datetime.date(2021, 1, 3),
datetime.date(2021, 1, 3),
datetime.date(2021, 1, 3),
datetime.date(2021, 1, 4),
],
"Flair": ["Discussion", "Due Diligence", "Due Diligence", "Discussion", "Discussion", "Hedge Fund Tears", "News", "News"],
})
data["Flair1"] = data.Flair.values
res = pandas.pivot_table(
data,
index=["Submission_Date"],
values=['Flair'],
columns=['Flair1'],
aggfunc='count',
fill_value=0
)
res = pandas.DataFrame(res.to_records())
res.columns = [col.replace("('Flair', ", '').replace(")", '') for col in res.columns]
res['Total'] = res.astype({col:float for col in res.columns if col != "Submission_Date"}).sum(numeric_only=True, axis=1)
res[[col for col in res.columns if col != "Submission_Date"]] = res[[col for col in res.columns if col != "Submission_Date"]].div(res.Total, axis=0)
res = res.drop(columns=['Total'])
print(res)

|