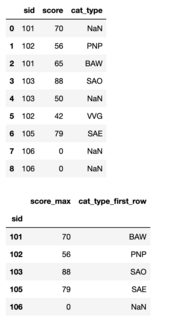
my sample df looks like this:
sid score cat_type
101 70 na
102 56 PNP
101 65 BAW
103 88 SAO
103 50 na
102 42 VVG
105 79 SAE
....
df_groupby = df.groupby(['sid']).agg(
score_max = ('score','max'),
cat_type_first_row = ('cat_type', '?')
)
with the group by, I want to get the first row value of cat_type that is not na and assign it to cat_type_first_row
my final df should look like this:
sid score_max cat_type_first_row
101 70 BAW
102 56 PNP
103 88 SAO
105 79 SAE
....
Could you please assist me in solving this problem?
CodePudding user response:
Try replace na to NaN and do first
df_groupby = df.replace('na',np.nan).groupby(['sid']).agg(
score_max = ('score','max'),
cat_type_first_row = ('cat_type', 'first')
)
df_groupby
score_max cat_type_first_row
sid
101 70 BAW
102 56 PNP
103 88 SAO
105 79 SAE
CodePudding user response:
If you do not want to drop any row, you could use:
(df.merge((df.dropna(subset=['cat_type'])
.groupby('sid')['cat_type']
.first()
.rename('cat_type_first_row')
), on='sid')
)
output:
sid score cat_type cat_type_first_row
0 101 70 NaN BAW
1 101 65 BAW BAW
2 102 56 PNP PNP
3 102 42 VVG PNP
4 103 88 SAO SAO
5 103 50 NaN SAO
6 105 79 SAE SAE
CodePudding user response:
You can define a function that takes as input the grouped pandas series. I've tested this code and got your desired output (added rows for cases when all cat_type values are np.nan for a group):
df = {
'sid': [101, 102, 101, 103, 103, 102, 105, 106, 106],
'score': [70, 56, 65, 88, 50, 42, 79, 0, 0],
'cat_type': [np.nan, 'PNP', 'BAW', 'SAO', np.nan, 'VVG', 'SAE', np.nan, np.nan]
}
df = pd.DataFrame(df)
display(df)
def get_cat_type_first_row(series):
series_nona = series.dropna()
if len(series_nona) == 0:
return np.nan
else:
return series.dropna().iloc[0]
df_groupby = df.groupby(['sid']).agg(
score_max = ('score','max'),
cat_type_first_row = ('cat_type', get_cat_type_first_row)
)
df_groupby
Output: