I have a shapefile containing thousands of multipolygons, and dozensof different shapefiles. Following I am providing a small example/code with some toy insatnces (A multipolygons gpds and two points gpds).
import pandas as pd
import numpy as np
import geopandas
from shapely.geometry import Polygon
import random
# Create polygons
p1 = Polygon( [(0, 0), (0, 1), (0.5, 0.5)])
p2 = Polygon([(.75, 0), (1, .5), (.75, 1), (1.75, 0)])
p3 = Polygon([(2, 0), (2, 1), (3, 0)])
polygons = gpd.GeoDataFrame([p1, p2, p3], columns={'geometry'})
polygons['name'] = ["a", "b", "c"]
# Create red points
redPoints = gpd.GeoDataFrame(gpd.points_from_xy( np.random.uniform(0, 3, 50), np.random.uniform(0, 1, 50)), columns = ['geometry'])
# Create green points
greenPoints = gpd.GeoDataFrame(gpd.points_from_xy( np.random.uniform(1, 3, 50), np.random.uniform(0, 1, 50)), columns = ['geometry'])
# plot polygons, red and green points
# ax = polygons.plot()
# redPoints.plot(ax = ax, c = 'r')
# greenPoints.plot(ax = ax, c = 'g')
I need to count the number of each type of points that is inside/intersects with eahc of the multipolygons and create a column specific for each point type. I know how to do this with two shapefiles, like something as follow:
# count green (g) points
gpointsInPolygon = gpd.sjoin(polygons,greenPoints, op='intersects')
gpointsInPolygon['number of green points']=1
gpointsInPolygon = gpointsInPolygon.groupby(['name']).agg({'number of green points':sum}).reset_index()
cgps = gpointsInPolygon.set_index('name').join(polygons.set_index('name'), how ='right')
cgps.fillna(0, inplace=True)
# count red (r) points
rpointsInPolygon = gpd.sjoin(polygons,redPoints, op='intersects')
rpointsInPolygon['number of red points']=1
rpointsInPolygon = rpointsInPolygon.groupby(['name']).agg({'number of red points':sum}).reset_index()
crps = rpointsInPolygon.set_index('name').join(polygons.set_index('name'), how ='right')
crps.fillna(0, inplace=True)
#crs
redgreens = pd.merge(cgps, crps, on="geometry")
result = pd.merge(redgreens, polygons, on='geometry' )
I think this is not an efficient way of doing this (no?). As I have more than 50 large shapefiles of different type of points. I am looking for an efficient way to implement this for large point shapefiles. Thanks!
CodePudding user response:
Can you combine all your points in one GeoDataFrame, have a name/category column ('red', 'blue', etc.), and then do the join just once? Something like this?
Your given data
import pandas as pd
import numpy as np
import geopandas as gpd
from shapely.geometry import Polygon
import random
import matplotlib.pyplot as plt
# Create polygons
p1 = Polygon([(0, 0), (0, 1), (0.5, 0.5)])
p2 = Polygon([(0.75, 0), (1, 0.5), (0.75, 1), (1.75, 0)])
p3 = Polygon([(2, 0), (2, 1), (3, 0)])
polygons = gpd.GeoDataFrame([p1, p2, p3], columns={"geometry"})
polygons["name"] = ["a", "b", "c"]
# Create red points
redPoints = gpd.GeoDataFrame(
gpd.points_from_xy(np.random.uniform(0, 3, 50), np.random.uniform(0, 1, 50)),
columns=["geometry"],
)
# Create green points
greenPoints = gpd.GeoDataFrame(
gpd.points_from_xy(np.random.uniform(1, 3, 50), np.random.uniform(0, 1, 50)),
columns=["geometry"],
)
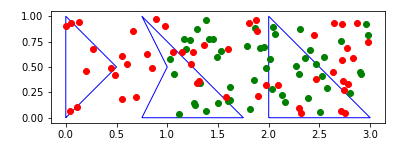
Plot it to check
fig, ax = plt.subplots()
polygons.plot(ax=ax, edgecolor="blue", color="none")
greenPoints.plot(ax=ax, c="green")
redPoints.plot(ax=ax, c="red")
Combine into one GeoDataFrame
greenPoints["name"] = "green"
redPoints["name"] = "red"
allPoints = pd.concat([greenPoints, redPoints], axis=0)
display(allPoints)

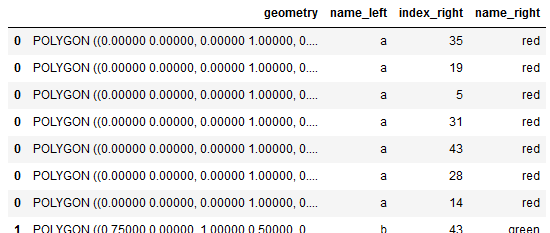
Intersect / Join polygons and points
intersect = gpd.sjoin(polygons, allPoints)
display(intersect)
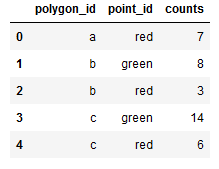
Counting (final answer)
mycounts = (
intersect.groupby(["name_left", "name_right"])
.size()
.reset_index(name="counts")
.rename(columns={"name_left": "polygon_id", "name_right": "point_id"})
)
display(mycounts)