I have a time series data set of multiple IDs and multiple variables, each variable has 3 time series entries - "baseline", "3 month", "6 month". The dataframe is structured like this, df =
import pandas as pd
data = {'Patient ID': [11111, 11111, 11111, 11111, 22222, 22222, 22222, 22222, 33333, 33333, 33333, 33333, 44444, 44444, 44444, 44444, 55555, 55555, 55555, 55555],
'Lab Attribute': ['% Saturation- Iron', 'ALK PHOS', 'ALT(SGPT)', 'AST (SGOT)', '% Saturation- Iron', 'ALK PHOS', 'ALT(SGPT)', 'AST (SGOT)', '% Saturation- Iron', 'ALK PHOS', 'ALT(SGPT)', 'AST (SGOT)', '% Saturation- Iron', 'ALK PHOS', 'ALT(SGPT)', 'AST (SGOT)', '% Saturation- Iron', 'ALK PHOS', 'ALT(SGPT)', 'AST (SGOT)'],
'Baseline': [46.0, 94.0, 21.0, 18.0, 46.0, 94.0, 21.0, 18.0, 46.0, 94.0, 21.0, 18.0, 46.0, 94.0, 21.0, 18.0, 46.0, 94.0, 21.0, 18.0],
'3 Month': [23.0, 82.0, 13.0, 17.0, 23.0, 82.0, 13.0, 17.0, 23.0, 82.0, 13.0, 17.0, 23.0, 82.0, 13.0, 17.0, 23.0, 82.0, 13.0, 17.0],
'6 Month': [34.0, 65.0, 10.0, 14.0, 34.0, 65.0, 10.0, 14.0, 34.0, 65.0, 10.0, 14.0, 34.0, 65.0, 10.0, 14.0, 34.0, 65.0, 10.0, 14.0]}
df = pd.DataFrame(data)
Patient ID Lab Attribute Baseline 3 Month 6 Month
0 11111 % Saturation- Iron 46.0 23.0 34.0
1 11111 ALK PHOS 94.0 82.0 65.0
2 11111 ALT(SGPT) 21.0 13.0 10.0
3 11111 AST (SGOT) 18.0 17.0 14.0
4 22222 % Saturation- Iron 46.0 23.0 34.0
5 22222 ALK PHOS 94.0 82.0 65.0
6 22222 ALT(SGPT) 21.0 13.0 10.0
7 22222 AST (SGOT) 18.0 17.0 14.0
8 33333 % Saturation- Iron 46.0 23.0 34.0
9 33333 ALK PHOS 94.0 82.0 65.0
10 33333 ALT(SGPT) 21.0 13.0 10.0
11 33333 AST (SGOT) 18.0 17.0 14.0
12 44444 % Saturation- Iron 46.0 23.0 34.0
13 44444 ALK PHOS 94.0 82.0 65.0
14 44444 ALT(SGPT) 21.0 13.0 10.0
15 44444 AST (SGOT) 18.0 17.0 14.0
16 55555 % Saturation- Iron 46.0 23.0 34.0
17 55555 ALK PHOS 94.0 82.0 65.0
18 55555 ALT(SGPT) 21.0 13.0 10.0
19 55555 AST (SGOT) 18.0 17.0 14.0
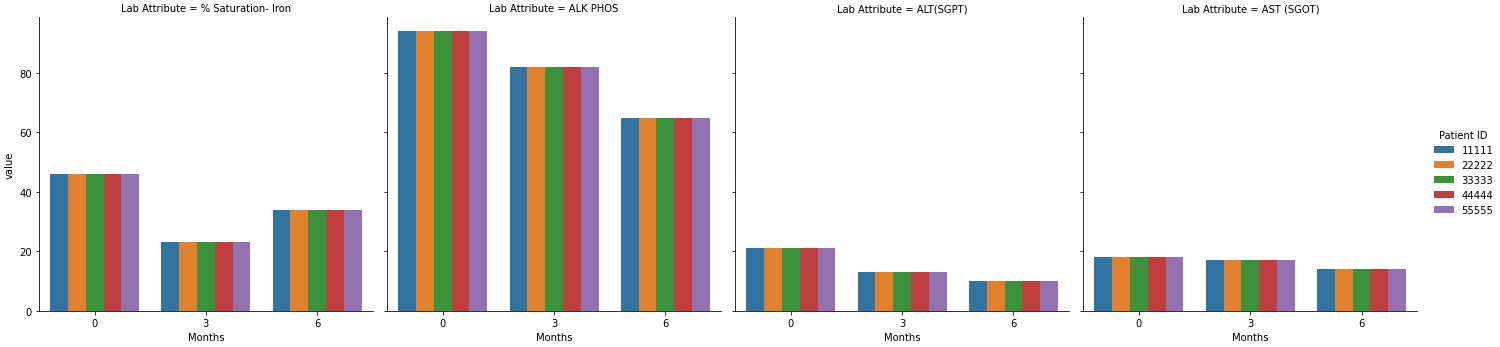
What I'm trying to do is group by the ID and Lab Attribute and create a plot of each "Lab Attribute" - % Saturation- Iron, ALK PHOS, etc., that will include the time series for all of the Patient IDs.
So based on the example data there would be 4 plots - % Saturation- Iron, ALK PHOS, etc., that each would contain 5 traces (1 for each ID).
I tried using groupby per this article - 
- Use