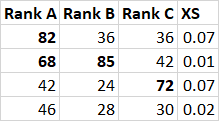
In Excel there is a handy function called AVERAGEIF(). Is there any way to do something similar with pandas? For example, in the following table I would like to get a series of the average XS for Rank > 50.
Desired result:

My code:
df[df[['Rank A', 'Rank B', 'Rank C']] > 50].loc[:, 'XS'].mean(axis=0)
Outputs:
nan
Note: There are a lot of questions addressing average of grouped aggregates, but I have not found any addressing this specific problem.
Note also, that I simplified the question for clarity. The tables that I am working with are 300K rows x 110 columns, and they are being calculated in 100x in a loop. Some optimization is called for. For example, vector math tends to be much faster than a map function which operates on each cell separately.
CodePudding user response:
We can create a mask for the DataFrame based on the condition, then use this indicator DataFrame as a filter and multiply this by the XS column. This will create either the XS or NaN values based on the mask location. We can then take the mean:
m = (df[['Rank A', 'Rank B', 'Rank C']] > 50)
res = m[m].mul(df['XS'], axis=0).mean(axis=0)
res:
Rank A 0.04
Rank B 0.01
Rank C 0.07
dtype: float64
We can add to_frame and transpose T:
res.to_frame(name='Average XS when rank > 50').T
Rank A Rank B Rank C
Average XS when rank > 50 0.04 0.01 0.07
m:
Rank A Rank B Rank C
0 True False False
1 True True False
2 False False True
3 False False False
m[m]:
Rank A Rank B Rank C
0 True NaN NaN
1 True True NaN
2 NaN NaN True
3 NaN NaN NaN
Then mulitply the new Series with the DataFrame on axis=0. True will be handled as 1 and NaN will produce NaN.
res = m[m].mul(df['XS'], axis=0).mean(axis=0)
Rank A Rank B Rank C
0 0.07 NaN NaN
1 0.01 0.01 NaN
2 NaN NaN 0.07
3 NaN NaN NaN
Now mean will work as expected since it will not consider NaN values when calculating the column average.
Setup:
import pandas as pd
df = pd.DataFrame({
'Rank A': [82, 68, 42, 46],
'Rank B': [36, 85, 24, 28],
'Rank C': [36, 42, 72, 30],
'XS': [0.07, 0.01, 0.07, 0.02]
})
CodePudding user response:
You can use mask and clip:
>>> df[['Rank A', 'Rank B', 'Rank C']].mask(lambda x: x <= 50).clip(0, 1) \
.mul(df[['XS']].values).mean()
Rank A 4.0
Rank B 1.0
Rank C 7.0
dtype: float64
If your column XS contains strings:
>>> df[['Rank A', 'Rank B', 'Rank C']] \
.mask(lambda x: x <= 50).clip(0, 1) \
.mul(df['XS'].str.strip('%').astype(float).to_frame().values).mean()
Rank A 4.0
Rank B 1.0
Rank C 7.0
dtype: float64
CodePudding user response:
df['Rank A'] = df.where(df['Rank A'] > 50)['XS'].mean()
df['Rank B'] = df.where(df['Rank B'] > 50)['XS'].mean()
df['Rank C'] = df.where(df['Rank C'] > 50)['XS'].mean()
df.drop('XS', axis=1, inplace=True)
df.drop_duplicates(inplace=True)
print(df)
output:
Rank A Rank B Rank C
0 0.04 0.01 0.07