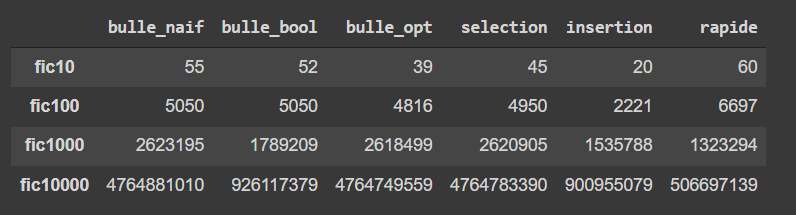
I have the following array : [['fic10', {'bulle_naif': '55'}, {'bulle_bool': '52'}, {'bulle_opt': '39'}, {'selection': '45'}, {'insertion': '20'}, {'rapide': '60'}], ['fic100', {'bulle_naif': '5050'}, {'bulle_bool': '5050'}, {'bulle_opt': '4816'}, {'selection': '4950'}, {'insertion': '2221'}, {'rapide': '6697'}], ['fic1000', {'bulle_naif': '2623195'}, {'bulle_bool': '1789209'}, {'bulle_opt': '2618499'}, {'selection': '2620905'}, {'insertion': '1535788'}, {'rapide': '1323294'}], ['fic10000', {'bulle_naif': '4764881010'}, {'bulle_bool': '926117379'}, {'bulle_opt': '4764749559'}, {'selection': '4764783390'}, {'insertion': '900955079'}, {'rapide': '506697139'}]]
And I convert it to a dataframe :
CodePudding user response:
Let's present your data in a way that's more easily understood by pandas.DataFrame.
First method: a dict with one entry key:list per column
The goal of this method is to rearrange your data so it looks like a single dict, with one entry per column, and a list of values for each column:
# {'bulle_naif': ['55', '5050', '2623195', '4764881010'],
# 'bulle_bool': ['52', '5050', '1789209', '926117379'],
# 'bulle_opt': ['39', '4816', '2618499', '4764749559'],
# 'selection': ['45', '4950', '2620905', '4764783390'],
# 'insertion': ['20', '2221', '1535788', '900955079'],
# 'rapide': ['60', '6697', '1323294', '506697139'],
# 'name': ['fic10', 'fic100', 'fic1000', 'fic10000']}
Here is the code to make that transformation:
import pandas as pd
raw_data = [['fic10', {'bulle_naif': '55'}, {'bulle_bool': '52'}, {'bulle_opt': '39'}, {'selection': '45'}, {'insertion': '20'}, {'rapide': '60'}], ['fic100', {'bulle_naif': '5050'}, {'bulle_bool': '5050'}, {'bulle_opt': '4816'}, {'selection': '4950'}, {'insertion': '2221'}, {'rapide': '6697'}], ['fic1000', {'bulle_naif': '2623195'}, {'bulle_bool': '1789209'}, {'bulle_opt': '2618499'}, {'selection': '2620905'}, {'insertion': '1535788'}, {'rapide': '1323294'}], ['fic10000', {'bulle_naif': '4764881010'}, {'bulle_bool': '926117379'}, {'bulle_opt': '4764749559'}, {'selection': '4764783390'}, {'insertion': '900955079'}, {'rapide': '506697139'}]]
cleaned_data = { k: [] for d in raw_data[0][1:] for k in d.keys() }
cleaned_data['name'] = []
for row in raw_data:
cleaned_data['name'].append(row[0])
for d in row[1:]:
for k,v in d.items():
cleaned_data[k].append(v)
print(cleaned_data)
# {'bulle_naif': ['55', '5050', '2623195', '4764881010'],
# 'bulle_bool': ['52', '5050', '1789209', '926117379'],
# 'bulle_opt': ['39', '4816', '2618499', '4764749559'],
# 'selection': ['45', '4950', '2620905', '4764783390'],
# 'insertion': ['20', '2221', '1535788', '900955079'],
# 'rapide': ['60', '6697', '1323294', '506697139'],
# 'name': ['fic10', 'fic100', 'fic1000', 'fic10000']}
# IMPORTANT NOTE
# This cleaning-up is a bit careless
# If a key is missing in one of the lists, the resulting data will be misaligned
# Making sure data is not misaligned:
assert(all(len(l) == len(cleaned_data['name']) for l in cleaned_data.values()))
good_dataframe = pd.DataFrame(cleaned_data).set_index('name')
print(good_dataframe)
# bulle_naif bulle_bool bulle_opt selection insertion rapide
# name
# fic10 55 52 39 45 20 60
# fic100 5050 5050 4816 4950 2221 6697
# fic1000 2623195 1789209 2618499 2620905 1535788 1323294
# fic10000 4764881010 926117379 4764749559 4764783390 900955079 506697139
Second method: a 2d array without keys but in order
If your data is already sorted so that bulle_naif, bulle_opt, etc, are already in the same order of every row, then you can get rid of all the dicts and provide pandas.DataFrame with a 2d array directly:
# assumes the rows of raw_data are all in the same order already
array_data = [[row[0]] [v for d in row[1:] for v in d.values()] for row in raw_data]
print(array_data)
# [['fic10', '55', '52', '39', '45', '20', '60'],
# ['fic100', '5050', '5050', '4816', '4950', '2221', '6697'],
# ['fic1000', '2623195', '1789209', '2618499', '2620905', '1535788', '1323294'],
# ['fic10000', '4764881010', '926117379', '4764749559', '4764783390', '900955079', '506697139']]
keys = ['name'] [k for d in raw_data[0][1:] for k in d.keys()]
dataframe = pd.DataFrame(array_data, columns = keys).set_index('name')
print(dataframe)
# bulle_naif bulle_bool bulle_opt selection insertion rapide
# name
# fic10 55 52 39 45 20 60
# fic100 5050 5050 4816 4950 2221 6697
# fic1000 2623195 1789209 2618499 2620905 1535788 1323294
# fic10000 4764881010 926117379 4764749559 4764783390 900955079 506697139
If you don't know that all the rows are already presented in the same order, you will have to sort them explicitly to make sure:
# I shuffled the entries in raw_data
raw_data = [
['fic10', {'bulle_bool': '52'}, {'bulle_naif': '55'}, {'selection': '45'}, {'insertion': '20'}, {'rapide': '60'}, {'bulle_opt': '39'}],
['fic100', {'bulle_opt': '4816'}, {'bulle_naif': '5050'}, {'insertion': '2221'}, {'selection': '4950'}, {'rapide': '6697'}, {'bulle_bool': '5050'}],
['fic1000', {'bulle_opt': '2618499'}, {'selection': '2620905'}, {'insertion': '1535788'}, {'bulle_bool': '1789209'}, {'rapide': '1323294'}, {'bulle_naif': '2623195'}],
['fic10000', {'selection': '4764783390'}, {'bulle_opt': '4764749559'}, {'bulle_bool': '926117379'}, {'bulle_naif': '4764881010'}, {'insertion': '900955079'}, {'rapide': '506697139'}]]
array_data = [[row[0]] [v for d in sorted(row[1:], key=lambda d: next(iter(d.keys()))) for v in d.values()] for row in raw_data]
print(array_data)
# [['fic10', '52', '55', '39', '20', '60', '45'],
# ['fic100', '5050', '5050', '4816', '2221', '6697', '4950'],
# ['fic1000', '1789209', '2623195', '2618499', '1535788', '1323294', '2620905'],
# ['fic10000', '926117379', '4764881010', '4764749559', '900955079', '506697139', '4764783390']]
CodePudding user response:
This is the simpler and easy to understand piece of code and may it help you to solve your problem.
import pandas as pd
array = [['fic10', {'bulle_naif': '55'}, {'bulle_bool': '52'}, {'bulle_opt': '39'}, {'selection': '45'}, {'insertion': '20'}, {'rapide': '60'}],
['fic100', {'bulle_naif': '5050'}, {'bulle_bool': '5050'}, {'bulle_opt': '4816'}, {'selection': '4950'}, {'insertion': '2221'}, {'rapide': '6697'}],
['fic1000', {'bulle_naif': '2623195'}, {'bulle_bool': '1789209'}, {'bulle_opt': '2618499'}, {'selection': '2620905'}, {'insertion': '1535788'}, {'rapide': '1323294'}],
['fic10000', {'bulle_naif': '4764881010'}, {'bulle_bool': '926117379'}, {'bulle_opt': '4764749559'}, {'selection': '4764783390'}, {'insertion': '900955079'}, {'rapide': '506697139'}]]
dt = pd.DataFrame()
for item in array:
tmp = pd.DataFrame(index=[item[0]])
for i in range(len(item)-1):
if i != 0:
for key, value in item[i].items():
tmp[key] = value
dt = dt.append(tmp)
print(dt)
Output:
bulle_naif bulle_bool bulle_opt selection insertion
fic10 55 52 39 45 20
fic100 5050 5050 4816 4950 2221
fic1000 2623195 1789209 2618499 2620905 1535788
fic10000 4764881010 926117379 4764749559 4764783390 900955079