I have a dataframe like as shown below
stud_name act_qtr year yr_qty qtr mov_avg_full mov_avg_2qtr_min_period
0 ABC Q2 2014 2014Q2 NaN NaN NaN
1 ABC Q1 2016 2016Q1 Q1 13.0 14.5
2 ABC Q4 2016 2016Q4 NaN NaN NaN
3 ABC Q4 2017 2017Q4 NaN NaN NaN
4 ABC Q4 2020 2020Q4 NaN NaN NaN
OP = pd.read_clipboard()
stud_name qtr year t_score p_score yr_qty mov_avg_full mov_avg_2qtr_min_period
0 ABC Q1 2014 10 11 2014Q1 10.000000 10.0
1 ABC Q1 2015 11 32 2015Q1 10.500000 10.5
2 ABC Q2 2015 13 45 2015Q2 11.333333 12.0
3 ABC Q3 2015 15 32 2015Q3 12.250000 14.0
4 ABC Q4 2015 17 21 2015Q4 13.200000 16.0
5 ABC Q1 2016 12 56 2016Q1 13.000000 14.5
6 ABC Q2 2017 312 87 2017Q2 55.714286 162.0
7 ABC Q3 2018 24 90 2018Q3 51.750000 168.0
df = pd.read_clipboard()
I would like to fillna() based on below logic
For ex: let's take stud_name = ABC. He has multipple NA records. Let's take his NA for 2020Q4. To fill that, we pick the latest record from df for stud_name=ABC before 2020Q4 (which is 2018Q3). Similarly, if we take stud_name = ABC. His another NA record is for 2014Q2. We pick the latest (prior) record from df for stud_name=ABC before 2014Q2 (which is 2014Q1). We need to sort based on yearqty values to get the latest (prior) record correctly
We need to do this for each stud_name and for a big dataset
So, we fillna in mov_avg_full and mov_avg_2qtr_min_period
If there are no previous records to look at in df dataframe, leave NA as it is
I was trying something like below but it doesn't work and incorrect
Filled = OP.merge(df,on=['stud_name'],how='left')
filled.sort_values(['year','Qty'],inplace=True)
filled['mov_avg_full'].fillna(Filled.groupby('stud_name']['mov_avg_full'].shift())
filled['mov_avg_2qtr_min_period'].fillna(Filled .groupby('stud_name']['mov_avg_2qtr_min_period'].shift())
I expect my output to be like as shown below
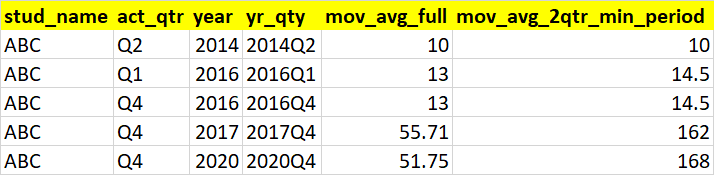
CodePudding user response:
In this case, you might want to use append instead of merge. In other words, you want to concatenate vertically instead of horizontally. Then after sorting the DataFrame by stud_name and yr_qtr, you can use groupby and fillna methods on it.
Code:
import pandas as pd
# Create the sample dataframes
import numpy as np
op = pd.DataFrame({'stud_name': {0: 'ABC', 1: 'ABC', 2: 'ABC', 3: 'ABC', 4: 'ABC'}, 'act_qtr': {0: 'Q2', 1: 'Q1', 2: 'Q4', 3: 'Q4', 4: 'Q4'}, 'year': {0: 2014, 1: 2016, 2: 2016, 3: 2017, 4: 2020}, 'yr_qty': {0: '2014Q2', 1: '2016Q1', 2: '2016Q4', 3: '2017Q4', 4: '2020Q4'}, 'qtr': {0: np.NaN, 1: 'Q1', 2: np.NaN, 3: np.NaN, 4: np.NaN}, 'mov_avg_full': {0: np.NaN, 1: 13.0, 2: np.NaN, 3: np.NaN, 4: np.NaN}, 'mov_avg_2qtr_min_period': {0: np.NaN, 1: 14.5, 2: np.NaN, 3: np.NaN, 4: np.NaN}})
df = pd.DataFrame({'stud_name': {0: 'ABC', 1: 'ABC', 2: 'ABC', 3: 'ABC', 4: 'ABC', 5: 'ABC', 6: 'ABC', 7: 'ABC'}, 'qtr': {0: 'Q1', 1: 'Q1', 2: 'Q2', 3: 'Q3', 4: 'Q4', 5: 'Q1', 6: 'Q2', 7: 'Q3'}, 'year': {0: 2014, 1: 2015, 2: 2015, 3: 2015, 4: 2015, 5: 2016, 6: 2017, 7: 2018}, 't_score': {0: 10, 1: 11, 2: 13, 3: 15, 4: 17, 5: 12, 6: 312, 7: 24}, 'p_score': {0: 11, 1: 32, 2: 45, 3: 32, 4: 21, 5: 56, 6: 87, 7: 90}, 'yr_qty': {0: '2014Q1', 1: '2015Q1', 2: '2015Q2', 3: '2015Q3', 4: '2015Q4', 5: '2016Q1', 6: '2017Q2', 7: '2018Q3'}, 'mov_avg_full': {0: 10.0, 1: 10.5, 2: 11.333333, 3: 12.25, 4: 13.2, 5: 13.0, 6: 55.714286, 7: 51.75}, 'mov_avg_2qtr_min_period': {0: 10.0, 1: 10.5, 2: 12.0, 3: 14.0, 4: 16.0, 5: 14.5, 6: 162.0, 7: 168.0}})
# Append df to op
dfa = op.append(df[['stud_name', 'yr_qty', 'mov_avg_full', 'mov_avg_2qtr_min_period']])
# Sort before applying fillna
dfa = dfa.sort_values(['stud_name', 'yr_qty'])
# Group by stud_name and apply ffill
dfa[['mov_avg_full', 'mov_avg_2qtr_min_period']] = dfa.groupby('stud_name')[['mov_avg_full', 'mov_avg_2qtr_min_period']].fillna(method='ffill')
# Extract the orginal rows from op and deal with columns
dfa = dfa[dfa.act_qtr.notna()].drop('qtr', axis=1)
print(dfa)
Output:
| stud_name | act_qtr | year | yr_qty | mov_avg_full | mov_avg_2qtr_min_period |
|---|---|---|---|---|---|
| ABC | Q2 | 2014 | 2014Q2 | 10 | 10 |
| ABC | Q1 | 2016 | 2016Q1 | 13 | 14.5 |
| ABC | Q4 | 2016 | 2016Q4 | 13 | 14.5 |
| ABC | Q4 | 2017 | 2017Q4 | 55.7143 | 162 |
| ABC | Q4 | 2020 | 2020Q4 | 51.75 | 168 |