I have the below data frame
d = {
"name":["RRR","RRR","RRR","RRR","RRR","ZZZ","ZZZ","ZZZ","ZZZ","ZZZ"],
"id":[1,1,2,2,3,2,3,3,4,4],"value":[12,13,1,44,22,21,23,53,64,9]
}
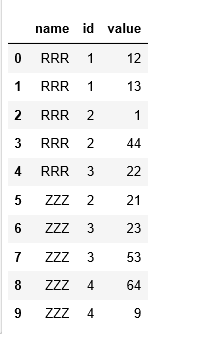
I want the out output as below:

CodePudding user response:
First pivot by DataFrame.set_index with counter by GroupBy.cumcount and DataFrame.unstack with helper column ind by id, then sorting second level of MultiIndex with flatten values:
df = (df.assign(ind = df['id'])
.set_index(['name','id', df.groupby(['name','id']).cumcount()])[['value', 'ind']]
.unstack(1)
.sort_index(axis=1, kind='mergesort', level=1))
df.columns = [f'{a}_{b}' for a, b in df.columns]
df = df.droplevel(1).reset_index()
print (df)
name ind_1 value_1 ind_2 value_2 ind_3 value_3 ind_4 value_4
0 RRR 1.0 12.0 2.0 1.0 3.0 22.0 NaN NaN
1 RRR 1.0 13.0 2.0 44.0 NaN NaN NaN NaN
2 ZZZ NaN NaN 2.0 21.0 3.0 23.0 4.0 64.0
3 ZZZ NaN NaN NaN NaN 3.0 53.0 4.0 9.0
CodePudding user response:
try this:
def func(sub: pd.DataFrame) ->pd.DataFrame:
dfs = [g.reset_index(drop=True).rename(
columns=lambda x: f'{x}_{n}') for n, g in sub.drop(columns='name').groupby('id')]
return pd.concat(dfs, axis=1)
res = df.groupby('name').apply(func).droplevel(1).reset_index()
print(res)
>>>
name id_1 value_1 id_2 value_2 id_3 value_3 id_4 value_4
0 RRR 1.0 12.0 2.0 1.0 3.0 22.0 NaN NaN
1 RRR 1.0 13.0 2.0 44.0 NaN NaN NaN NaN
2 ZZZ NaN NaN 2.0 21.0 3.0 23.0 4.0 64.0
3 ZZZ NaN NaN NaN NaN 3.0 53.0 4.0 9.0