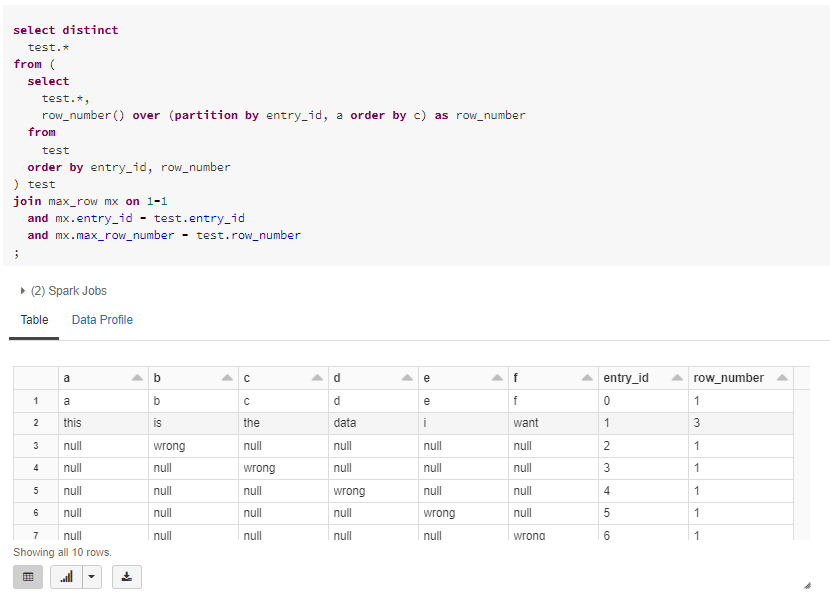
Problem:
I'm having trouble getting just one record per category in Databricks. For example, I would like to get a single row for each of the entry_id values in the sample data below.
Sample data:
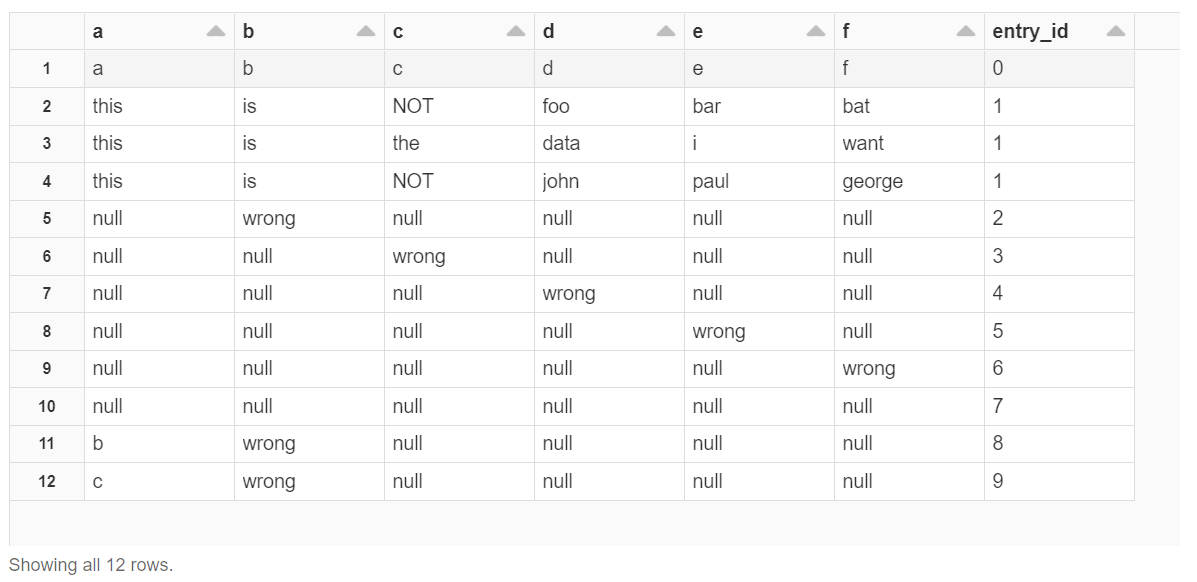
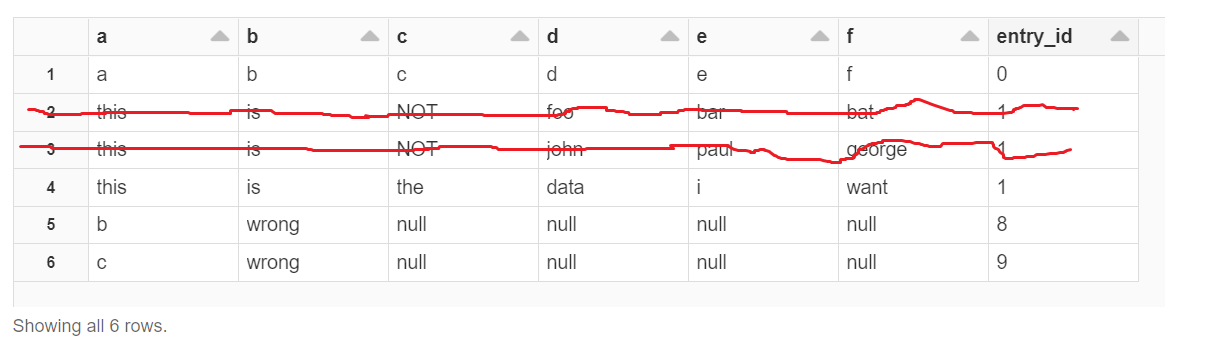
Almost what I want:
How do I get just the last row for each category? There could be multiple identical records and/or multiple records with different values. This is noise in the data that needs to be eliminated by selecting exactly one record.
The complete sql is below:
-- * * *
--
-- INIT THE SESSION
--
-- * * *
create database if not exists test;
use test;
set spark.sql.legacy.timeParserPolicy = LEGACY;
set spark.sql.legacy.parquet.datetimeRebaseModeInWrite = LEGACY;
select concat('using: ', 'test') as message;
drop table if exists test;
create table test as (
select 'a' a, 'b' b, 'c' c, 'd' d, 'e' e, 'f' f, 0 entry_id
union all
select 'this','is','NOT','foo','bar','bat', 1
union all
select 'this','is','NOT','john','paul','george', 1
union all
select 'this','is','the','data','i','want', 1
union all
select null, 'wrong', null, null, null, null, 2
union all
select null, null, 'wrong', null, null, null, 3
union all
select null, null, null, 'wrong', null, null, 4
union all
select null, null, null, null, 'wrong', null, 5
union all
select null, null, null, null, null, 'wrong', 6
union all
select null, null, null, null, null, null, 7
union all
select 'b', 'wrong', null, null, null, null, 8
union all
select 'c', 'wrong', null, null, null, null, 9
);
select * from test order by entry_id;
drop table if exists max_a;
create table max_a as (
select
entry_id,
max(a) a
from
test
group by 1
order by 1
);
select * from max_a;
select
test.*
from
max_a join test on max_a.a = test.a
order by entry_id
;
select
test.*
from
max_a join test on max_a.a = test.a
where test.entry_id = 1
;
CodePudding user response:
Databricks Runtime 10.0 and above supports