I have a dataset similar to below, I want to compare all rows for each inventory item based on the conditions that
if "value" column is not null, then flag it "yes"
Else if "value" column for all row (per each inventory) is null, then evaluate the "item" column, if either "item" column is not null, then that row should be flagged "yes". Or 1 record under "value" is null where 2 records under "value" is not null, then those 2 rows need to be evaluated based on the item
In the case that if both "value" and "item" are both null(per each inventory), evaluate the "year" column and flag the most updated year "yes". Or "value" is null but 1 record under "item" is null where 2 records under "item" is not null, then evaluate the "year" column and flag the most updated year "yes"
df['flag'].fillna('no',inplace=True)
I can set up this if then else logic but I don't know how to compare current row with 2 previous rows. The groupby with transform and custom function are great advices and I wonder how to capture all these scenarios or if there is a better way.
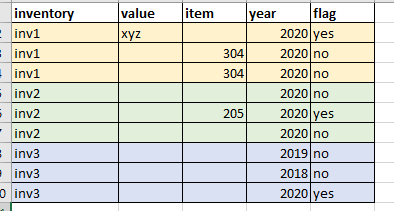
Below is how the simplified df would look like. In my real dataset, as described above, there are also cases that for the same inventory, "value" column are all null, but there are 2 rows under "item" are not null, in that case, "year" column needs to be evaluated for those 2 rows.
df1 = { 'inventory':['inv1','inv1','inv1','inv2','inv2','inv2','inv3','inv3','inv3'],
'value':['xyz','','','','','','','',''],
'item':['','304','304','','205','','','',''],
'year':[2020,2020,2020,2020,2020,2020,2019,2018,2020]}
df1=pd.DataFrame(df1)
desired output would be like below - adding a flag column to flag 'yes'/'no' based on the above multiple condtions.
CodePudding user response:
You can write your rules into a custom function and apply it to each group:
# Replace blank spaces with NaN
df1 = df1.replace('', np.nan)
def make_flag_col(subdf):
if subdf['value'].any():
return subdf['value'].notna()
elif subdf['item'].any():
return subdf['item'].notna()
else:
return subdf['year'] == subdf['year'].max()
df1['flag'] = (df1.groupby('inventory', group_keys=False)
.apply(make_flag_col)
.replace({True: 'yes', False: 'no'}))
print(df1)
inventory value item year flag
0 inv1 xyz NaN 2020 yes
1 inv1 NaN 304 2020 no
2 inv1 NaN 304 2020 no
3 inv2 NaN NaN 2020 no
4 inv2 NaN 205 2020 yes
5 inv2 NaN NaN 2020 no
6 inv3 NaN NaN 2019 no
7 inv3 NaN NaN 2018 no
8 inv3 NaN NaN 2020 yes
CodePudding user response:
This is actually not very complex. You mostly need a few groupby transform combinations. Here's a vectorized (read: very fast) solution:
df = df.replace('', np.nan)
cond = (
df['value'].notna() |
(df['value'].isna().groupby(df['inventory']).transform('all')
& df['item'].notna()) |
(df[['value', 'item']].isna().groupby(df['inventory']).transform('all').all(axis=1) &
(df['year'] == df.groupby('inventory')['year'].transform('max')))
)
df['flag'] = cond.map({True: 'yes', False: 'no'})
Output:
>>> df
inventory value item year flag
0 inv1 xyz NaN 2020 yes
1 inv1 NaN 304 2020 no
2 inv1 NaN 304 2020 no
3 inv2 NaN NaN 2020 no
4 inv2 NaN 205 2020 yes
5 inv2 NaN NaN 2020 no
6 inv3 NaN NaN 2019 no
7 inv3 NaN NaN 2018 no
8 inv3 NaN NaN 2020 yes