I have a script I am writing that gets a bunch of information and adds it into some lists, then I add those lists into a dictionary. Here is what the dictionary looks like:
{'0.001': ('16.36', '35.45', '48.15', '99.96'), '0.1': ('11.10', '43.40', '45.49', '99.99'), '0.2': ('12.49', '35.67', '51.85', '100.01'), '0.3': ('16.71', '28.27', '55.04', '100.02'), '0.5': ('23.71', '20.65', '55.63', '99.99'), '0.75': ('32.50', '15.83', '51.68', '100.01'), '1.0': ('39.24', '14.21', '46.57', '100.02'), '2.0': ('55.06', '11.05', '33.91', '100.02'), '3.0': ('59.81', '6.72', '33.44', '99.97')}
For every key there are four values associated with it.
I want each key to be its own row, and each value to be in a new column in that same row.
Here is my code so far:
periods = []
interface_sum = []
intraslab_sum = []
crustal_sum = []
total_sums = []
out = dict(zip(periods, zip(interface_sum, intraslab_sum, crustal_sum, total_sums)))
with open ('dict.csv','w', newline='') as csv_file:
writer = csv.writer(csv_file)
for key, value in out.items():
writer.writerow([key, value])
Those lists are populated with information seen here:
periods = ['0.001', '0.1', '0.2', '0.3', '0.5', '0.75', '1.0', '2.0', '3.0']
interface_sum = ['16.36', '11.10', '12.49', '16.71', '23.71', '32.50', '39.24', '55.06', '59.81']
intraslab_sum = ['35.45', '43.40', '35.67', '28.27', '20.65', '15.83', '14.21', '11.05', '6.72']
crustal_sum = ['48.15', '45.49', '51.85', '55.04', '55.63', '51.68', '46.57', '33.91', '33.44']
total_sum = ['99.96', '99.99', '100.01', '100.02', '99.99', '100.01', '100.02', '100.02', '99.97']
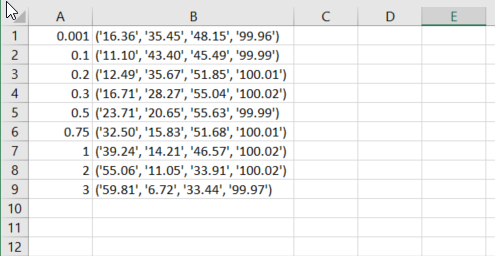
The periods is what I want the key to be, and the next 4 lists are the values. Here is an image of the csv output, it puts the keys into its own column and makes a new row for each one which I want but then the values with each key are all put in the same B column, and I want each value in its own column. So the first row 0.001, I want 16.36 in column B, then 35.45 in column, C, and so on. Any idea how to get this done?
CodePudding user response:
You are almost there. You can unpack the value tuple with * when creating each row list
with open ('dict.csv','w', newline='') as csv_file:
writer = csv.writer(csv_file)
for key, value in out.items():
writer.writerow([key, *value])
That could be shortened a bit to
with open ('dict.csv','w', newline='') as csv_file:
csv.writer(csv_file).writerows([k, *v] for k,v in out.items())
CodePudding user response:
Given:
vals={'0.001': ('16.36', '35.45', '48.15', '99.96'), '0.1': ('11.10', '43.40', '45.49', '99.99'), '0.2': ('12.49', '35.67', '51.85', '100.01'), '0.3': ('16.71', '28.27', '55.04', '100.02'), '0.5': ('23.71', '20.65', '55.63', '99.99'), '0.75': ('32.50', '15.83', '51.68', '100.01'), '1.0': ('39.24', '14.21', '46.57', '100.02'), '2.0': ('55.06', '11.05', '33.91', '100.02'), '3.0': ('59.81', '6.72', '33.44', '99.97')}
First make a list of the values you want:
keys=['periods','interface_sum','intraslab_sum','crustal_sum','total_sums']
Then you can make a dict of those keys associated with a reformatted list:
di={k:[v[0]] list(v[1]) for k,v in zip(keys, vals.items())}
>>> di
{'periods': ['0.001', '16.36', '35.45', '48.15', '99.96'], 'interface_sum': ['0.1', '11.10', '43.40', '45.49', '99.99'], 'intraslab_sum': ['0.2', '12.49', '35.67', '51.85', '100.01'], 'crustal_sum': ['0.3', '16.71', '28.27', '55.04', '100.02'], 'total_sums': ['0.5', '23.71', '20.65', '55.63', '99.99']}
If you just want to join the key values with the associated tuple:
new_vals=[[k] list(v) for k,v in vals.items()]
>>> new_vals
[['0.001', '16.36', '35.45', '48.15', '99.96'], ['0.1', '11.10', '43.40', '45.49', '99.99'], ['0.2', '12.49', '35.67', '51.85', '100.01'], ['0.3', '16.71', '28.27', '55.04', '100.02'], ['0.5', '23.71', '20.65', '55.63', '99.99'], ['0.75', '32.50', '15.83', '51.68', '100.01'], ['1.0', '39.24', '14.21', '46.57', '100.02'], ['2.0', '55.06', '11.05', '33.91', '100.02'], ['3.0', '59.81', '6.72', '33.44', '99.97']]