I want to write a function that finds the top three Free apps based on 'Reviews', 'Rating', 'Installs'.
It should return a data frame that has the category and app for the first two columns, and one of Rating, Installs, and Reviews as the third column
right now my code looks like this:
input:
def topthree(column):
Googleapps_df["Reviews"] = pd.to_numeric(Googleapps_df["Reviews"])
Googleapps_df["Installs"] = pd.to_numeric(Googleapps_df["Installs"])
Googleapps_df["Rating"] = pd.to_numeric(Googleapps_df["Rating"])
topthree = Googleapps_df.groupby('Type')[column].nlargest(3)
return topthree
topthree('Reviews')
output:
Type
Free 1879 44893888.0
1670 44891723.0
1704 44891723.0
Paid 4034 408292.0
7417 348962.0
8860 190086.0
Name: Reviews, dtype: float64
How do I add an app column in between the type and numbers, and how do I get rid of the 3 Paid number so it looks like this:
Type App
Free "App_name" 1879 44893888.0
"App_name" 1670 44891723.0
"App_name" 1704 44891723.0
Name: Reviews, dtype: float64
CodePudding user response:
You can use a filter to only show your results of where Type == 'Free' either after the .groupby('Type') or when you call the function.
Additionally, you can append your table with Googleapps_df['App'] since currently you are just showing the grouby tree that you have with Type and column.
CodePudding user response:
As you do not need the second type first filter that then find the max value of each of the three columns. Use:
import pandas as pd
df = pd.DataFrame({'name':['a','b','c','d','f','g','h','i'],'type':[1,2,2,1,1,1,2,2],'reviews':[500,4,350,102,35,40,4,350],'ratings':[8,45,822,23,74,100,4,350],'installs':[4,5,6,7,81,1,4,350]})
df1=df[df['type']==1]
n1 = df1[(df1['reviews']==df1['reviews'].max())]['name'].values[0]
n2 = df1[(df1['ratings']==df1['ratings'].max())]['name'].values[0]
n3 = df1[(df1['installs']==df1['installs'].max())]['name'].values[0]
out = pd.DataFrame({'name': [n1,n2,n3], 'values': vals})
Input:
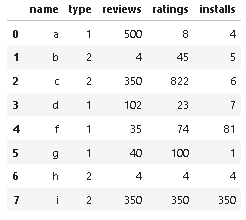
Output:

CodePudding user response:
Change:
topthree = Googleapps_df.groupby('Type')[column].nlargest(3)
to GroupBy.head with sorting by both columns by DataFrame.sort_values:
(topthree = Googleapps_df.sort_values(['Type',column], ascending=True, False)
.groupby('Type')[column]
.head(3))
Or convert column App to index:
(topthree = Googleapps_df.set_index('App')
.groupby('Type')[column]
.nlargest(3))
If need Series from first solution set it after groupby.head:
topthree = (Googleapps_df.sort_values(['Type',column], ascending=True, False)
.groupby('Type')[column]
.head(3)
.set_index(['Type', 'App'])[column])