I have a dataframe that looks like this:
| ID | memory confidence | Test (1= correct, 2=incorrect) | Experiment |
|---|---|---|---|
| 1 | 56 | 1 | Experiment 1 |
| 1 | 78 | 0 | Experiment 1 |
| 1 | 98 | 0 | Experiment 1 |
| 1 | 24 | 1 | Experiment 2 |
| 2 | 45 | 0 | Experiment 2 |
| 2 | 87 | 1 | Experiment 2 |
I want to see if a person's average confidence is correlated with their performance on the test. So I have written the following code, which shows a persons average memory confidence, and their average score:
df3 = df.groupby(['PID'])['accuracy','memory_confidence'].mean()
i = sns.lmplot(x = 'memory_confidence', y = 'accuracy', data = df3)
What I want to do now is to compute different correlations/ lmplots for Experiment 1 and Experiment 2
adding in 'source' does not work, as I get KeyError: "['source'] not in index"
df3 = df.groupby(['PID','source'])['accuracy','memory_confidence'].mean()
i = sns.lmplot(x = 'memory_confidence', y = 'accuracy', hue='source', data = df3)
CodePudding user response:
import numpy as np
import pandas as pd
df = pd.DataFrame([
[1, 56, 1, 'Experiment 1'],
[1, 78, 0, 'Experiment 1'],
[1, 98, 0, 'Experiment 1'],
[1, 24, 1, 'Experiment 2'],
[2, 45, 0, 'Experiment 2'],
[2, 87, 1, 'Experiment 2']
], columns=['ID', 'memory_confidence', 'accuracy', 'Experiment'])
sns.lmplot(x = 'memory_confidence', y = 'accuracy', hue='Experiment', data=df)
plt.show()
exp1 = df[df['Experiment'] == 'Experiment 1']
exp1_corr = exp1.corr().loc['memory_confidence', 'accuracy']
exp2 = df[df['Experiment'] == 'Experiment 2']
exp2_corr = exp2.corr().loc['memory_confidence', 'accuracy']
print(exp1_corr, exp2_corr)
Produces the following:
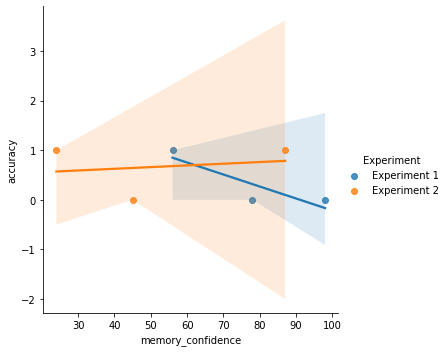
-0.8794395358869003 0.18898223650461368