I would like to check my work and understanding of pipelines, unfortunately MARS doesn't accommodate this feature so it is hard to verify my hypothesis.
I placed the instructions in a spreadsheet to help me understand what is going on and I would like to ensure that this is correct. I used the color blue to indicate each stage in the cycle, unlike the book, I didn't denote which half of the cycle each stage occurs (I.E WB is in the first half and ID in the second half)
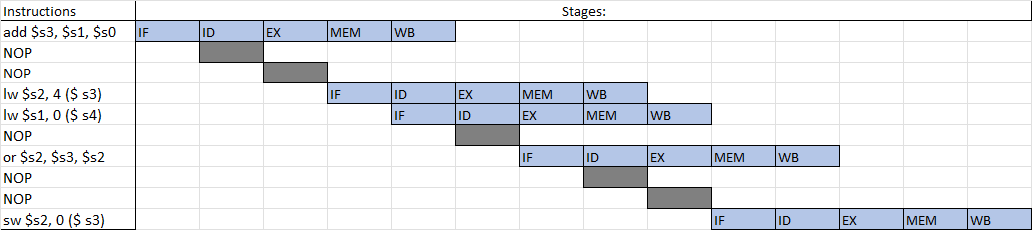
Based on the book by Patterson and Hennessey, the ID stage occurs towards the end while WB is at the start.
So that should mean that the last SW command should work as intended because the WB of the prior (valid instruction) occurs at the start of that cycle - while ID is at the tail.
CodePudding user response:
Yes, that looks correct.
The ID stage of a succeeding instruction can overlap with the WB stage of a preceding instruction, and still get the proper value.
This is because, for one in WB, the new data is fully ready to go into the registers at the very start of the cycle — there is nothing to compute; the complete answers have been fully computed by the end of the prior cycle, so no bits need change in the values being recorded by the write back. (Compare with ALU operation where substantial logic follows input from the prior cycle, before outputs can be computed.)
In the ID stage, the values are looked up in the register file, and either the cycle timing will be sufficiently long to allow the values to settle to include newly written WB values that happen in the same cycle, or else the designers will put an internal bypass/forward inside the register file. Either way, the ID stage will obtain the latest value of a register that is written (WB) in the same cycle rather than a prior stale value.
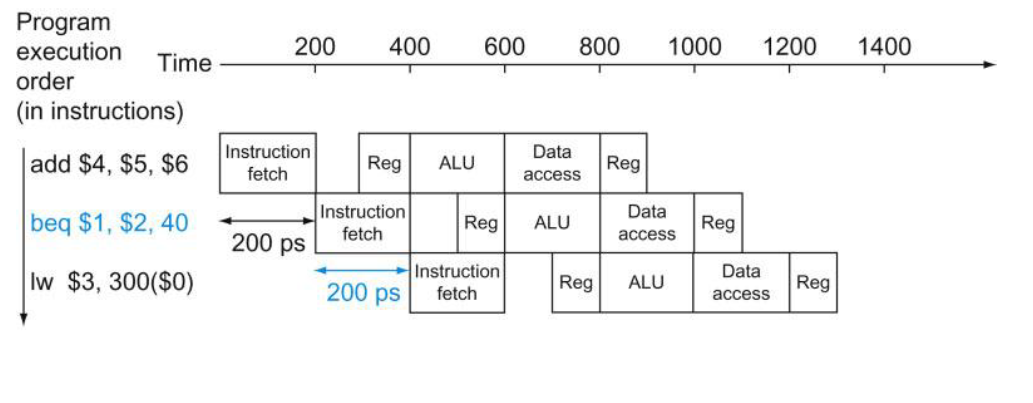
The way they have put it is that WB happens in the first half of the cycle and ID happens in the second half. However it is actually implemented internally to various processors — the idea is that we can count on reading values written in the same cycle. (I believe they leave it unsaid as to whether they are suggesting to use the other transition of the clock (e.g. the downward edge) to physically divide the cycle in half or not, but that is another implementation possibility.)
From the same text book:
(A read of a register during a clock cycle returns the value written at the end of the first half of the cycle, when such a write occurs.)
Caption on Figure 4.52, and,
The last potential hazard can be resolved by the design of the register file hardware: What happens when a register is read and written in the same clock cycle? We assume that the write is in the first half of the clock cycle and the read is in the second half, so the read delivers what is written. As is the case for many implementations of register files, we have no data hazard in this case.
From main text just above the Figure 4.52. These same texts occurs in the RISC V version of the book (though relative to Figure number 4.50 instead of 4.52).
Let's also note that when forwarding (aka bypassing) is introduced to mitigate hazards (instead of programmer inserting nops), there will need to be forwarding from EX->EX as well as MEM->EX. The first is for back to back RAW hazards on the ALU, where the second is for both load-use RAW hazards (back to back) as well as ALU hazards that are separated by 1 instruction!