An application (the underlying code of which can't be modified) is running a select statement against a relatively large table (~1.8M rows, 2GB) and creating a huge performance bottleneck on the DB server.
The table itself has approx. 120 columns of varying datatype. The select statement is selecting about 100 of those columns based on values of 2 columns which have both been indexed individually and together.
e.g.
SELECT
column1,
column2,
column3,
column4,
column5,
and so on.....
FROM
ITINDETAIL
WHERE
(column23 = 1 AND column96 = 1463522)
However, SQL Server chooses to ignore the index and instead scans the clustered (PK) index which takes forever (this was cancelled after 42 seconds, it's been known to take over 8 minutes on a busy production DB).
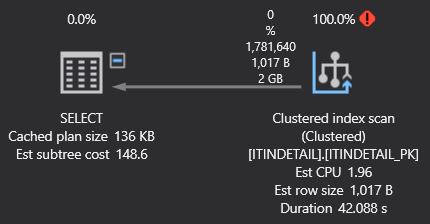
If I simply change the select statement, replacing all columns with just a select count(*) , the index is used and results return in milliseconds.

EDIT: I believe ITINDETAIL_004 (where column23 and column96 have been indexed together) is the index that should be getting used for the original statement.
Confusingly, if I create a non-clustered index on the table for the two columns in the where clause like this:
CREATE NONCLUSTERED INDEX [ITINDETAIL20220504]
ON [ITINDETAIL] ([column23] ASC, [column96] ASC)
INCLUDE (column1, column2, column3, column4, column5,
and so on..... )
and include ALL other columns from the select statement in the index (in my mind, this is essentially just creating a TABLE!), then run the original select statement, the new HUGE index is used and results are returned very quickly:
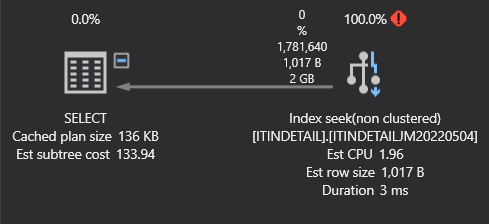
However, I'm not sure this is the right way to address the problem.
How can I force SQL Server to use what I think is the correct index?
Version is: SQL Server 2017
CodePudding user response:
Based on additional details from the comments, it appears that the index you want SQL Server to use isn't a covering index; this means that the index doesn't contain all the columns that are referenced in the query. As such, if SQL Server were to use said index, then it would need to first do a seek on the index, and then perform a key lookup on the clustered index to get the full details of the row. Such lookups can be expensive.
As a result of the index you want not being covering, SQL Server has determined that the index you want it to to use would produce an inferior query plan to simply scanning the entire clustered index; which is by definition covering as it INCLUDEs all other columns not in the CLUSTERED INDEX.
For your index ITINDETAIL20220504 you have INCLUDEd all the columns that are in your SELECT, which means that it is covering. This means that SQL Server can perform a seek on the index, and get all the information it needs from that seek; which is far less costly that a seek followed by a key lookup and quicker than a scan of the entire clustered index. This is why this information works.
We coould put this into some kind of analogy using a Library type scenario, which is full of Books, to help explain this idea more:
Let's say that the Clustered Index is a list of every book in the library sorted by it's ISBN number (The Primary Key). Along side that ISBN number you have the details of the Author, Title, Publication Date, Publisher, If it's hardcover or softcover, the colour of the spine, the section of the Library the Book is located in, the book case, and the shelf.
Now let's say you want to obtain any books by the the Author Brandon Sanderson published on or after 2015-01-01. If you then wanted to you could go through the entire list, one by one, finding the books by that author, checking the publication date, and then writing down it's location so you can go and visit each of those locations and collect the book. This is effectively a Clustered Index Scan.
Now let's say you have a list of all the books in the Library again. The list contains the Author, Publication Date, and the ISBN (The Primary Key), and is ordered by the Author and the Publication Date. You want to fulfil the same task; obtain any books by the the Author Brandon Sanderson published on or after 2015-01-01. Now you can easily go through that list and find all those books, but you don't know where they are. As a result even after you have gone straight to the Brandon Sanderson "section" of the list, you'll still need to write all the ISBNs down, and then find each of those ISBN in the original list, get their location and title. This is your index ITINDETAIL_004; you can easily find the rows you want to filter to, but you don't have all the information so you have to go somewhere else afterwards.
Lastly we have a 3rd list, this list is ordered by the author and then publication date (like the 2nd list), but also includes the Title, the section of the Library the Book is located in, the book case, and the shelf, as well as the ISBN (Primary key). This list is ideal for your task; it's in the right order, as you can easily go to Brandon Sanderson and then the first book published on or after 2015-01-01, and it has the title and location of the book. This is your INDEX ITINDETAIL20220504 would be; it has the information in the order you want, and contains all the information you asked for.
Saying all this, you can force SQL Server to choose the index, but as I said in my 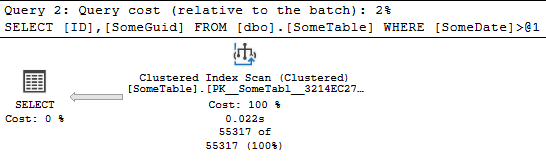
Ok, let's add an index on SomeDate and run the query again:
CREATE INDEX IX_NonCoveringIndex ON dbo.SomeTable (SomeDate);
GO
--Index Scan of Clustered index
SELECT ID,
SomeGuid
FROM dbo.SomeTable
WHERE SomeDate > '20220504';
Same result, and SSMS has even suggested an index:

Now, as I mentioned, you can force SQL Server to use a specific index. Let's do that and see what happens:
SELECT ID,
SomeGuid
FROM dbo.SomeTable WITH (INDEX(IX_NonCoveringIndex))
WHERE SomeDate > '20220504';
And this gives exactly the plan I suggested; A key lookup:
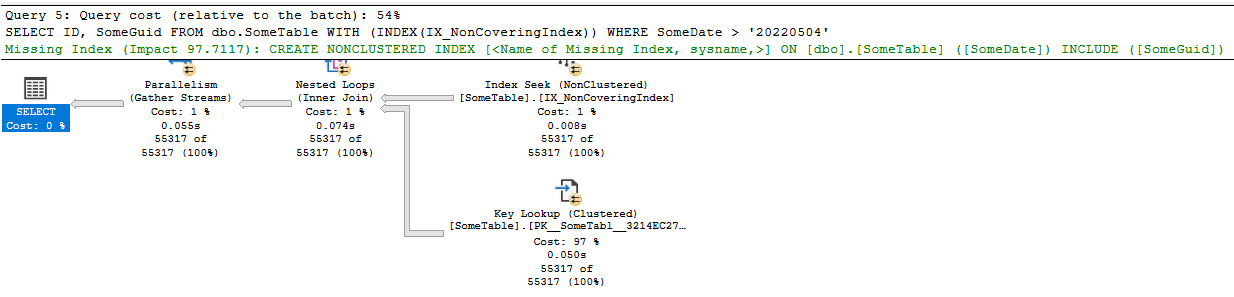
This is expensive. In fact, if we turn on the statistics for IO and Time, the query without the index hint took 40ms, the one with the hint took 107ms in the first run. Subsequent runs all had the second query taking around double the time of the first. IO wise the first query has a simple scan and 398 logical reads; the latter had 5 scans and 114403 logical reads!
Now, finally, let's add that covering Index and run:
CREATE INDEX IX_CoveringIndex ON dbo.SomeTable (SomeDate) INCLUDE (SomeGuid);
GO
SELECT ID,
SomeGuid
FROM dbo.SomeTable
WHERE SomeDate > '20220504';
Here we can see that seek we wanted:
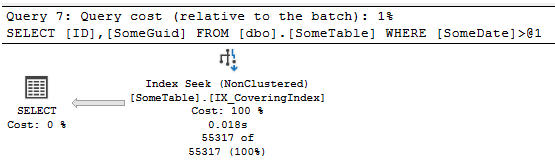
If we look at the IO and times again compared to the prior 2, we get 1 scan, 202 logical reads, and it was running in about 25ms.