I am trying to take this data and turn it into a dataframe in pandas:
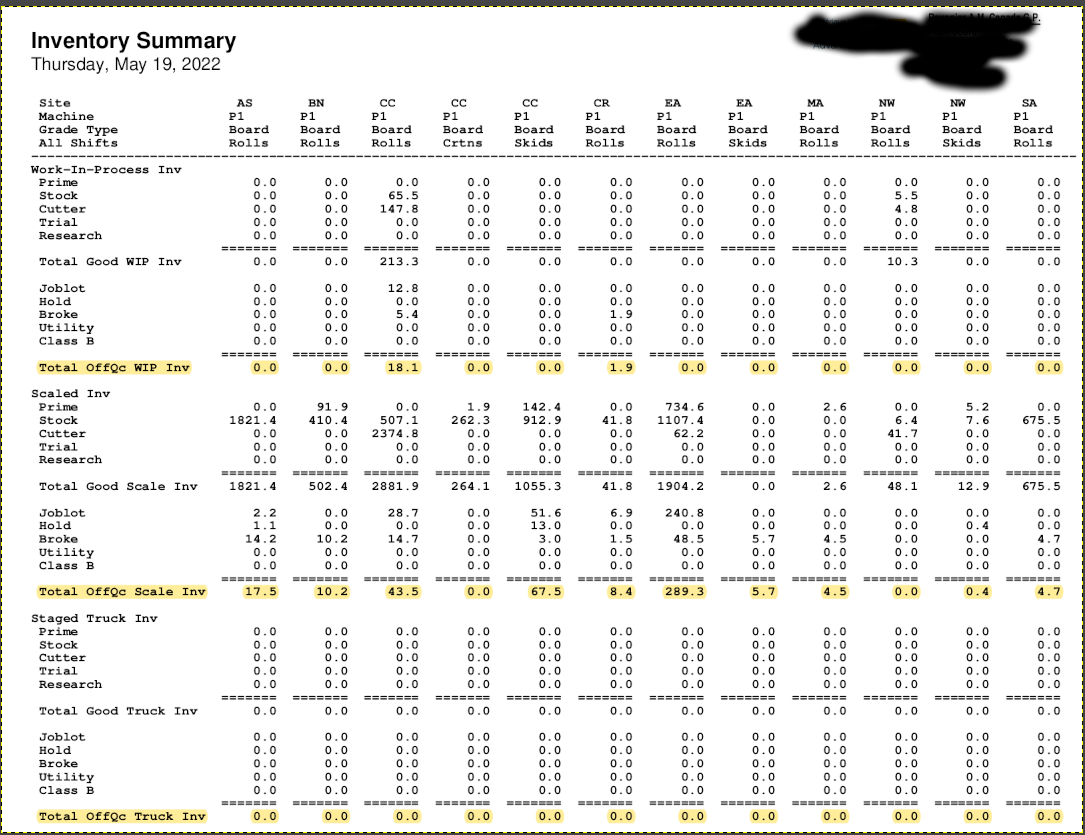
I am using camelot and it is "working" however, I am only getting 2 columns with this code:
import camelot
tables = camelot.read_pdf('Inventory_Summary.pdf', flavor='stream')
print(tables[0])
what is happening is it is considering everything on the left side 1 columns and the blacked out information the only information in the 2nd column
I want just the informaiton below the date into a dataframe
any help you can provide whould be great!
Thanks!
-littlejiver
CodePudding user response:
You have what appears to be an ideal tabular source for setting your zone of interest, and you should also have the fallback of using poppler pdftotext in python (which I do not use) You have not supplied your minimal input for testing so taking a poor similar input I suggest you could do something like this when needing a reliable fixed area, at worst re-print that as a fresh pdf for your input.
so here a similar poor source (not mine so can not control the cropped pdf data that is off page, but I could if desired change width to crop that hidden data too.

So here is perhaps a desired output (including hidden columns) shown on screen, but could be output to a text file for adding (post extraction) character separation as say csv file or simpler imported as plain column text to excel.
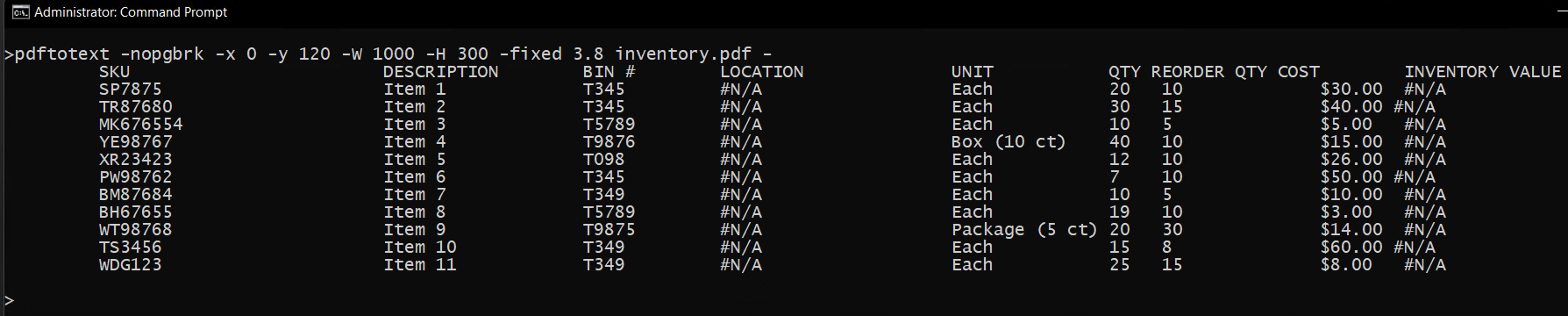
pdftotext -nopgbrk -x 0 -y 120 -W 1000 -H 300 -fixed 3.8 inventory.pdf -
where pdftotext options can be seen from pdftotext -h on any relevant command line
CodePudding user response:
This is how I solved it...
import PyPDF2
import pandas as pd
import numpy as np
lines = []
sites = []
kinds = []
total_offqc_wip_inv = []
total_offqc_scale_inv = []
total_offqc_truck_inv = []
total_offqc_rail_inv = []
total_offqc_boat_inv = []
# creating a pdf file object
pdfFileObj = open('PDFs/Inventory_Summary.pdf', 'rb')
# creating a pdf reader object
pdfReader = PyPDF2.PdfFileReader(pdfFileObj)
count = pdfReader.numPages
# creating a page object
pageObj0 = pdfReader.getPage(0)
pageObj1 = pdfReader.getPage(1)
pageObj2 = pdfReader.getPage(2)
pageObj3 = pdfReader.getPage(3)
pageObj4 = pdfReader.getPage(4)
pageObj5 = pdfReader.getPage(5)
# extracting text from page
page0 = pageObj0.extractText().strip()
page1 = pageObj1.extractText().strip()
page2 = pageObj2.extractText().strip()
page3 = pageObj3.extractText().strip()
page4 = pageObj4.extractText().strip()
page5 = pageObj5.extractText().strip()
corrected_page0 = page0.split('07:43am')[ 1]
corrected_page1 = page1.split('07:43am')[ 1]
corrected_page2 = page2.split('07:43am')[ 1]
corrected_page3 = page3.split('07:43am')[ 1]
corrected_page4 = page4.split('07:43am')[ 1]
corrected_page5 = page5.split('07:43am')[ 1]
for line in page0.splitlines():
if 'Site' in line:
for word in line.split():
if word != 'Site':
sites.append(word)
if 'All Shifts' in line:
for word in line.split():
if word != 'All':
if word != 'Shifts':
kinds.append(word)
if 'Total OffQc WIP Inv' in line:
for word in line.split():
if word != 'Total':
if word != 'OffQc':
if word != 'WIP':
if word != 'Inv':
total_offqc_wip_inv.append(word)
if 'Total OffQc Scale Inv' in line:
for word in line.split():
if word != 'Total':
if word != 'OffQc':
if word != 'Scale':
if word != 'Inv':
total_offqc_scale_inv.append(word)
if 'Total OffQc Truck Inv' in line:
for word in line.split():
if word != 'Total':
if word != 'OffQc':
if word != 'Truck':
if word != 'Inv':
total_offqc_truck_inv.append(word)
for line in page1.splitlines():
if 'Total OffQc Rail Inv' in line:
for word in line.split():
if word != 'Total':
if word != 'OffQc':
if word != 'Rail':
if word != 'Inv':
total_offqc_rail_inv.append(word)
if 'Total OffQc Boat Inv' in line:
for word in line.split():
if word != 'Total':
if word != 'OffQc':
if word != 'Boat':
if word != 'Inv':
total_offqc_boat_inv.append(word)
for line in page3.splitlines():
if 'Site' in line:
for word in line.split():
if word != 'Site':
sites.append(word)
if 'All Shifts' in line:
for word in line.split():
if word != 'All':
if word != 'Shifts':
kinds.append(word)
if 'Total OffQc WIP Inv' in line:
for word in line.split():
if word != 'Total':
if word != 'OffQc':
if word != 'WIP':
if word != 'Inv':
total_offqc_wip_inv.append(word)
if 'Total OffQc Scale Inv' in line:
for word in line.split():
if word != 'Total':
if word != 'OffQc':
if word != 'Scale':
if word != 'Inv':
total_offqc_scale_inv.append(word)
if 'Total OffQc Truck Inv' in line:
for word in line.split():
if word != 'Total':
if word != 'OffQc':
if word != 'Truck':
if word != 'Inv':
total_offqc_truck_inv.append(word)
for line in page4.splitlines():
if 'Total OffQc Rail Inv' in line:
for word in line.split():
if word != 'Total':
if word != 'OffQc':
if word != 'Rail':
if word != 'Inv':
total_offqc_rail_inv.append(word)
if 'Total OffQc Boat Inv' in line:
for word in line.split():
if word != 'Total':
if word != 'OffQc':
if word != 'Boat':
if word != 'Inv':
total_offqc_boat_inv.append(word)
sites.append("Total")
d = np.column_stack([sites, kinds, total_offqc_wip_inv, total_offqc_scale_inv, total_offqc_truck_inv, total_offqc_rail_inv, total_offqc_boat_inv])
df = pd.DataFrame(d)
# closing the pdf file object
pdfFileObj.close()