I have the following toy data
a = pd.DataFrame({"chkin": ["2022-05-22", "2022-05-22", "2022-05-23", "2022-05-24"],
"chkout": ["2022-05-25", "2022-05-23", "2022-05-26", "2022-05-27"],
"rtype": ["A", "A", "A", "A"],
"nbooked": [1, 2, 3, 1],
"nrooms": [10, 10, 10, 10]})
b = pd.DataFrame({"chkin": ["2022-05-22", "2022-05-23", "2022-05-23", "2022-05-24"],
"chkout": ["2022-05-24", "2022-05-26", "2022-05-24", "2022-05-25"],
"rtype": ["B", "B", "B", "B"],
"nbooked": [2, 1, 1, 3],
"nrooms": [12, 12, 12, 12]})
booking = pd.concat([a, b], axis=0, ignore_index=True, sort=False)
booking["chkin"] = pd.to_datetime(booking["chkin"])
booking["chkout"] = pd.to_datetime(booking["chkout"])
My problem is explained in the following figure
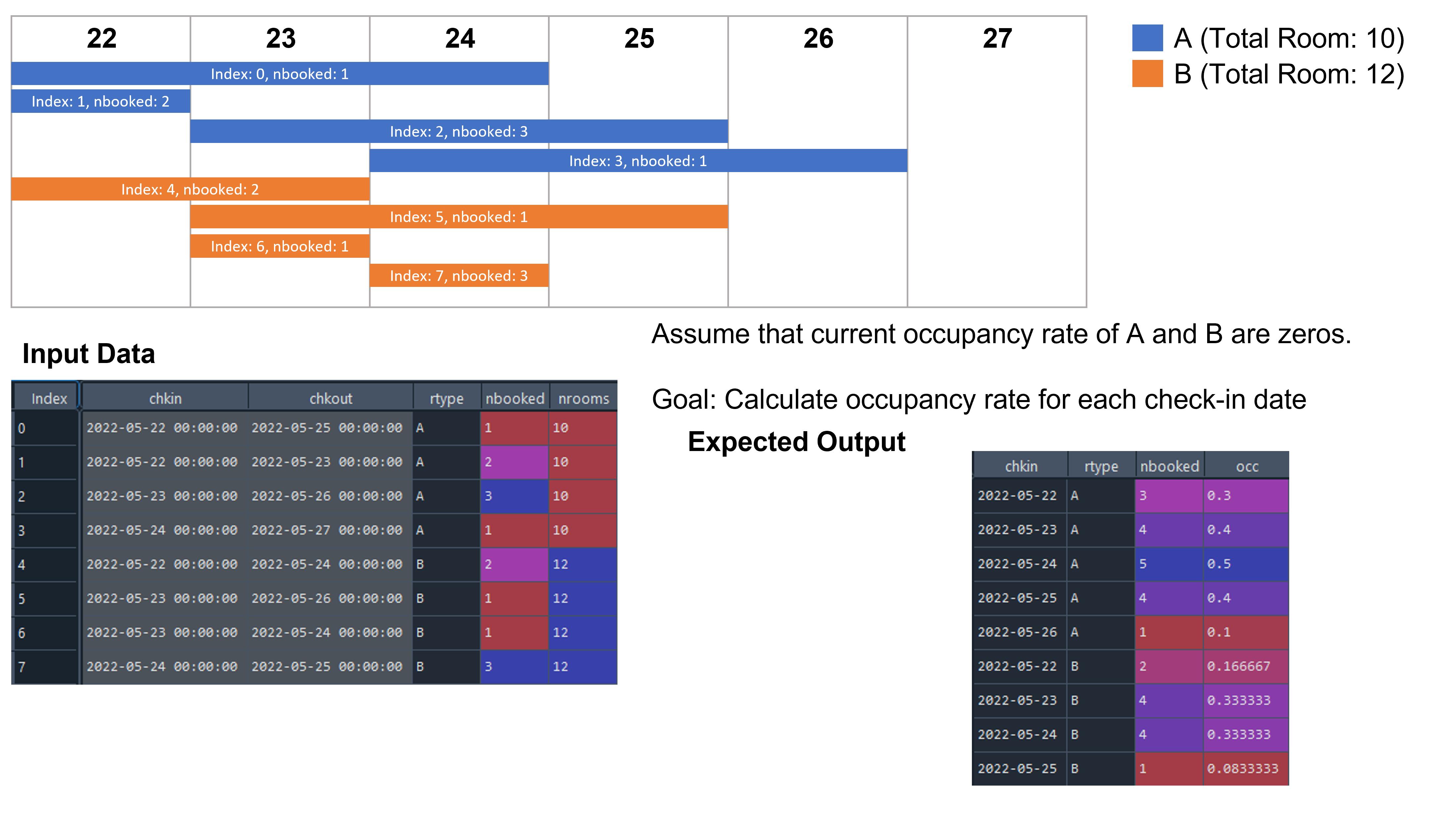
The nbooked refers to the number of booked rooms. Each color bar on calendar represents each row of input data. I would like to calculate occupancy rate for each day starts from the earliest check-in date to the last check-in date. (Assume that occupancy rate for each room type are zeros).
Since each day is possible to have check-in and check-out as shown in the calendar. Combining nbooked directly should not guarantee to get correct answer. May I have suggestions how to effectively calculate
CodePudding user response:
You could create a date range and then explode it, allowing you to groupby and sum for each day. The creation of the date range and explode will be a bit slow if your DataFrame is long.
This will also only give you dates in the output for which the occupancy is non-zero. If you also need the zeroes, reindex over the list of dates you care about.
booking['chkout_2'] = booking.chkout - pd.offsets.DateOffset(days=1)
booking['date'] = booking.apply(lambda r: pd.date_range(r.chkin, r.chkout_2, freq='D'), axis=1)
res = (booking.set_index(['rtype', 'nbooked', 'nrooms'])
.explode('date')
.reset_index()
.groupby(['rtype', 'date'])
.agg({'nbooked': 'sum', 'nrooms': 'max'}))
res['occ'] = res['nbooked']/res['nrooms']
print(res)
nbooked nrooms occ
rtype date
A 2022-05-22 3 10 0.300000
2022-05-23 4 10 0.400000
2022-05-24 5 10 0.500000
2022-05-25 4 10 0.400000
2022-05-26 1 10 0.100000
B 2022-05-22 2 12 0.166667
2022-05-23 4 12 0.333333
2022-05-24 4 12 0.333333
2022-05-25 1 12 0.083333
Another option, which may be more performant if you have a small set of dates that are relevant for each 'rtype', is to do a cross join to all dates and then filter down to the rows you care about. Output is identical to the above.
# Daily df of relevant dates
df_dates = pd.DataFrame({'date': pd.date_range('2022-05-22', '2022-05-25', freq='D')})
res = (booking.merge(df_dates, how='cross')
.query('date >= chkin & date < chkout')
.groupby(['rtype', 'date'])
.agg({'nbooked': 'sum', 'nrooms': 'max'}))
res['occ'] = res['nbooked']/res['nrooms']