I have the following code:
library(ggplot2)
library(ggsn) # for scale bar `scalebar`
library(fiftystater)
library(tidyverse)
ggplot(data= data.to.work.african, aes(map_id = State_L))
ggtitle("African American")
geom_map(aes(fill = Suicide_Rate_By_Pop), color= "white", map = fifty_states)
expand_limits(x = fifty_states$long, y = fifty_states$lat)
coord_map()
geom_text(data = fifty_states %>%
group_by(id) %>%
summarise(lat = mean(c(max(lat), min(lat))),
long = mean(c(max(long), min(long)))) %>%
mutate(State_L = id) %>%
left_join(data.to.work.african, by = "State_L"), size=2,
aes(x = long, y = lat, label = paste(Acronym, Suicide_Rate_By_Pop, sep = '\n'))
)
scale_x_continuous(breaks = NULL)
scale_y_continuous(breaks = NULL)
labs(x = "", y = "")
labs(fill = "Suicides Rate by 100,000 inhabitants")
scale_fill_gradientn(colours=rev(heat.colors(10)),na.value="grey90",
guide = guide_colourbar(barwidth = 25, barheight = 0.4,
#put legend title on top of legend
title.position = "top")
)
theme(legend.position = "bottom",
legend.title=element_text(size=10),
legend.text=element_text(size=08))
and the result is:
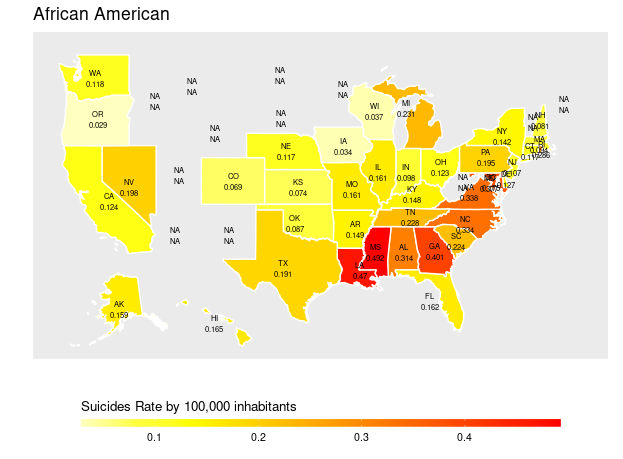
In my data set I did not have information for all states, because this, some states on map present the 'NA' result and has not line around it's own area.
How I would fix this problem? I would like to present the name of state for that one that has no line on my data set, like MT.
Data
# The data extracted from dput is:
structure(list(Acronym = c("AL", "AK", "AR", "CA", "CO", "CT",
"DE", "DC", "FL", "GA", "HI", "IL", "IN", "IA", "KS", "KY", "LA",
"MD", "MA", "MI", "MS", "MO", "NE", "NV", "NH", "NJ", "NY", "NC",
"OH", "OK", "OR", "PA", "RI", "SC", "TN", "TX", "VA", "WA", "WI"
), State_U = c("Alabama", "Alaska", "Arkansas", "California",
"Colorado", "Connecticut", "Delaware", "District of Columbia",
"Florida", "Georgia", "Hawaii", "Illinois", "Indiana", "Iowa",
"Kansas", "Kentucky", "Louisiana", "Maryland", "Massachusetts",
"Michigan", "Mississippi", "Missouri", "Nebraska", "Nevada",
"New Hampshire", "New Jersey", "New York", "North Carolina",
"Ohio", "Oklahoma", "Oregon", "Pennsylvania", "Rhode Island",
"South Carolina", "Tennessee", "Texas", "Virginia", "Washington",
"Wisconsin"), State_L = c("alabama", "alaska", "arkansas", "california",
"colorado", "connecticut", "delaware", "district of columbia",
"florida", "georgia", "hawaii", "illinois", "indiana", "iowa",
"kansas", "kentucky", "louisiana", "maryland", "massachusetts",
"michigan", "mississippi", "missouri", "nebraska", "nevada",
"new hampshire", "new jersey", "new york", "north carolina",
"ohio", "oklahoma", "oregon", "pennsylvania", "rhode island",
"south carolina", "tennessee", "texas", "virginia", "washington",
"wisconsin"), Race = c("African American", "African American",
"African American", "African American", "African American", "African American",
"African American", "African American", "African American", "African American",
"African American", "African American", "African American", "African American",
"African American", "African American", "African American", "African American",
"African American", "African American", "African American", "African American",
"African American", "African American", "African American", "African American",
"African American", "African American", "African American", "African American",
"African American", "African American", "African American", "African American",
"African American", "African American", "African American", "African American",
"African American"), Suicide_Rates = c(14L, 1L, 4L, 42L, 3L,
4L, 1L, 1L, 26L, 33L, 2L, 20L, 6L, 1L, 2L, 6L, 21L, 20L, 6L,
23L, 14L, 9L, 2L, 4L, 1L, 9L, 27L, 27L, 14L, 3L, 1L, 24L, 3L,
9L, 13L, 40L, 24L, 7L, 2L), Population = c(4452173L, 627963L,
2678588L, 33987977L, 4326921L, 3411777L, 786373L, 572046L, 16047515L,
8227303L, 1213519L, 12434161L, 6091866L, 2929067L, 2693681L,
4049021L, 4471885L, 5311034L, 6361104L, 9952450L, 2848353L, 5607285L,
1713820L, 2018741L, 1239882L, 8430621L, 19001780L, 8081614L,
11363543L, 3454365L, 3429708L, 12284173L, 1050268L, 4024223L,
5703719L, 20944499L, 7105817L, 5910512L, 5373999L), Suicide_Rate_By_Pop = c(0,
0, 0, 0.124, 0, 0, 0, 0, 0.162, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0.142, 0, 0, 0, 0, 0, 0, 0, 0, 0.191, 0,
NA, 0)), row.names = c(1L, 4L, 11L, 14L, 18L, 22L, 26L, 28L,
30L, 34L, 38L, 44L, 48L, 51L, 54L, 58L, 61L, 65L, 69L, 73L, 80L,
84L, 88L, 92L, 96L, 99L, 106L, 110L, 116L, 119L, 123L, 127L,
131L, 133L, 138L, 142L, 150L, 153L, 158L), class = "data.frame")
# I read it's .csv using
data.to.work.african <- read.csv2("dataSuicideAfrican.csv", sep = ';',
stringsAsFactors=FALSE,
header = TRUE)
CodePudding user response:
The problem is not in the ggplot code per se, rather the data. In the geom_text part of the ggplot the labels return NA because your current data.to.work.african data have only 39 states, and the fifty_states data has 51. You can overcome this by:
- Identifying the missing states using
setdiff() - Adding these state names to your
State_Lcolumn indata.to.work.africandataset - Converting state names to acronyms using
state.abb()function
The rerun your code and all good!
Code:
# Find missing states
missing_states <- setdiff(unique(fifty_states$id), data.to.work.african$State_L)
#> missing_states
# [1] "arizona" "idaho" "maine" "minnesota" "montana" "new mexico"
# [7] "north dakota" "south dakota" "utah" "vermont" "west virginia" "wyoming"
# add missing states to `data.to.work.african` dataset
currows <- nrow(data.to.work.african) # current number of rows
# add state names
data.to.work.african[(currows 1):(currows length(missing_states)),"State_L"] <- missing_states
# add acronyms
data.to.work.african[(currows 1):(currows length(missing_states)),"Acronym"] <- state.abb[match(missing_states,tolower(state.name))]
Rerunning your code:
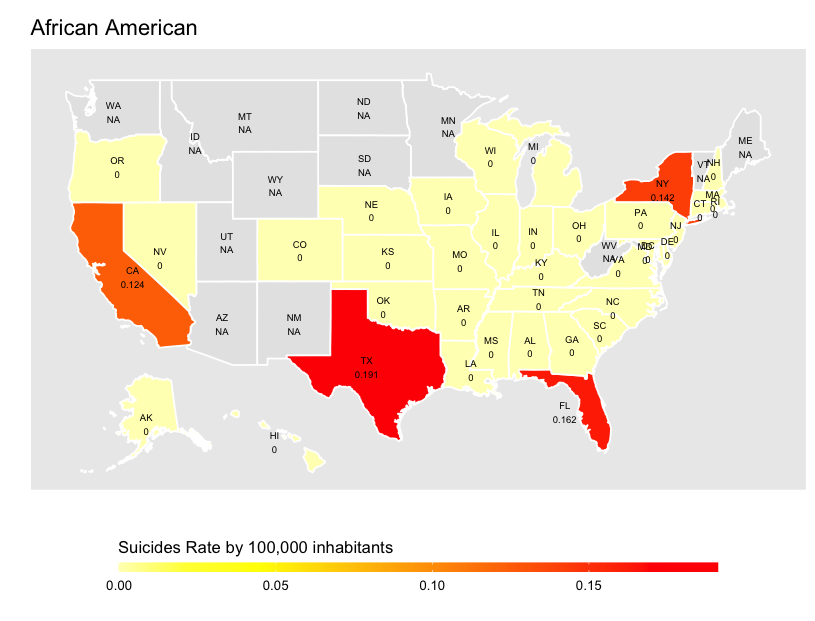
Note that the fiftystater package is not available for current versions of R, but the fifty_states data can be found here on Github