I have been trying to split this string but it only gives me the last character of the username I want. for example
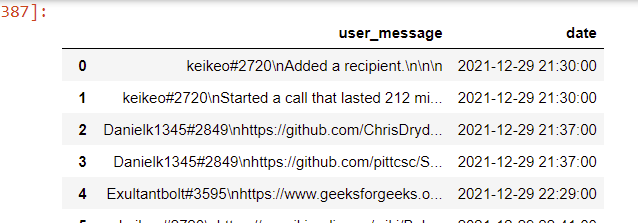
in this dataset I want to separate the username from the actual message but after doing this code-
#how can we separate users from messages
users = []
messages = []
for message in df['user_message']:
entry = re.split('([a-zA-Z]|[0-9]) #[0-9] \\n', message)
if entry[1:]:
users.append(entry[1])
messages.append(entry[2])
else:
users.append('notif')
messages.append(entry[0])
df['user'] = users
df['message'] = messages
df.drop(columns=['user_message'], inplace = True)
df.head(30)
I only get
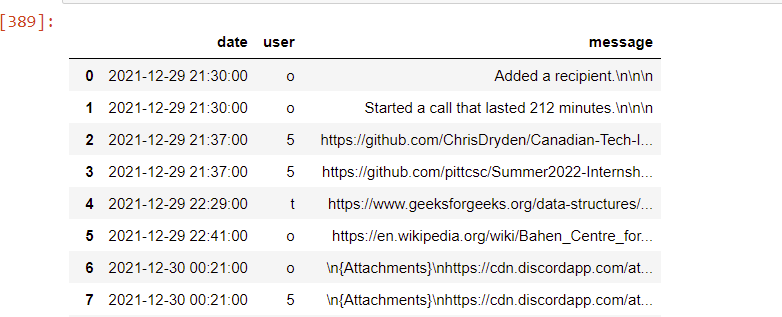
Could someone please tell me why it only gives me the last character of the string i want to split and how I can fix it? thanks a lot. This means a lot
CodePudding user response:
Splitting is not really the string operation you want here. Instead, just use str.extract directly on the user_message column:
df["username"] = df["user_message"].str.extract(r'^([^#] )')
The above logic will extract the leading part of the user message, from the beginning, until reaching the first hash symbol.
CodePudding user response:
You could do this a lot simpler, by just using string.split() and setting the maxsplit to 1. See the example below.
Note that regex is very useful, but it's very easy to get incorrect results with it. I advise to use a online regex validator if you really need to use it. As for the actual regex, your is in the wrong place. You need move it inside the group. I used regex101.com for testing...
([a-zA-Z0-9] )#[0-9] \\n
string.split() example:
line = "keikeo#2720\nAdded a recipient.\n\n\n"
user, message = line.split('\n', maxsplit=1)
print(user)
print(message)