I created a 2-dimensional random datasets (composed from a dataset of points and a column of labels) for centroid based k-means clustering in MATLAB where each point is represented by a vector of X and Y (the point coordinates) and each label represents the data point cluster,see example in figure below.
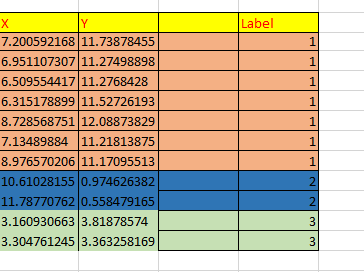
I applied the K-means clustering algorithm on these point datasets. I need help with the following: What function can I use to evaluate the accuracy of the K-means algorithm? In more detail: My aim is to score the Kmeans algorithm based on how many assigned labels it correctly identifies by comparing with assigned numbers by matlab. For example, I verify if the point (7.200592168, 11.73878455) is assigned with the point (6.951107307, 11.27498898) to the same cluster... etc.
CodePudding user response:
You are trying to minimize the total squared distance between each point and the mean coordinate of it's cluster.
CodePudding user response:
If I correctly understand your question, you are looking for the adjusted rand index. This will score the similarity between your matlab labels and your k-means labels.
Alternatively you can create a confusion matrix to visualise the mapping between your two labelsets.