I'm new to Machine Learning and Neural Nets and am experimenting with a configuration I found in a 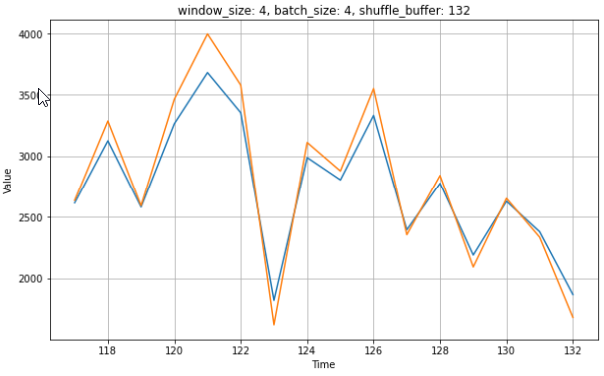
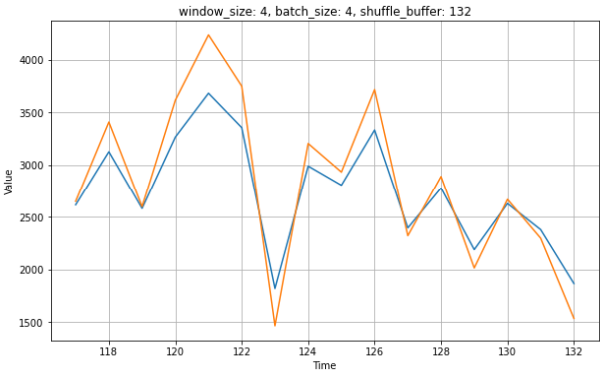
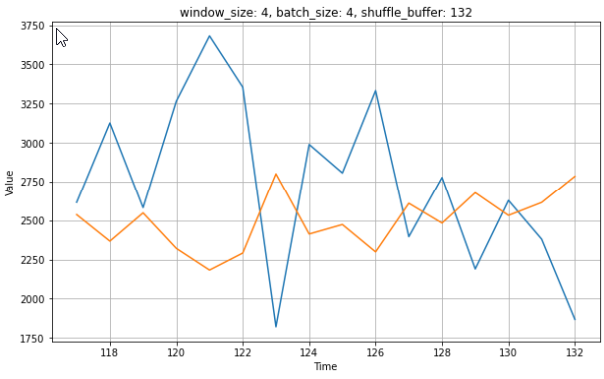
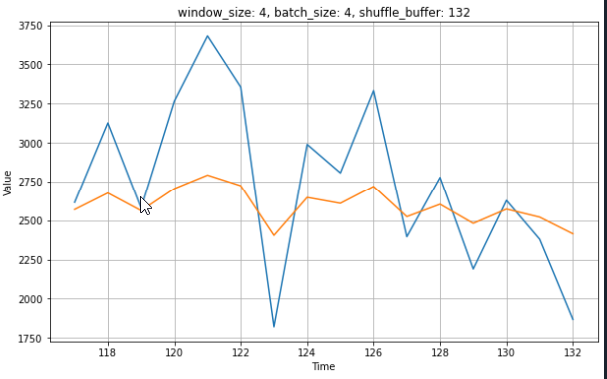
I thought that might has to something with the shuffling and size of shuffle_buffer, but this also happens for different sizes of shuffle_buffer, e.g. 20.
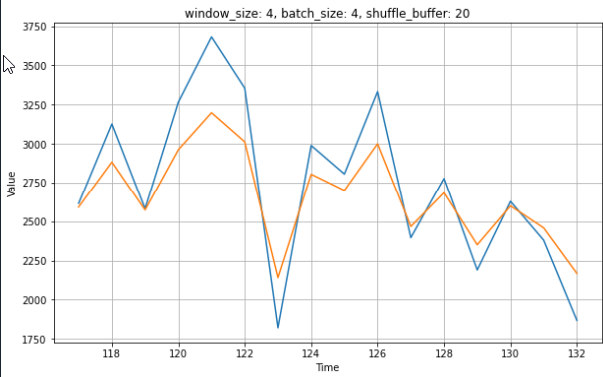
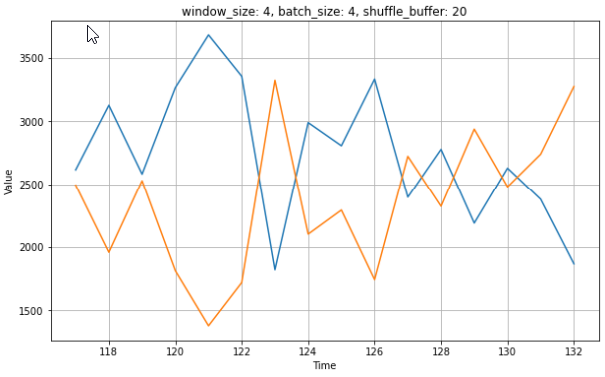
What is the reason for this behaviour and how to prevent this?
The code:
#%% Initializing
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from tensorflow import keras
#%% Defining the series
series = np.array([ 218, 555, 550, 563, 2492, 2848, 4041, 1302, 1040, 1073, 1392, 2093,
1870, 2328, 2102, 2844, 1730, 2431, 1974, 2450, 1975, 1415, 2568, 2831,
3011, 2576, 2825, 3327, 3539, 3392, 2949, 3283, 3854, 3918, 2639, 3826,
3980, 3134, 3997, 2708, 3257, 3435, 3337, 2571, 3370, 4277, 3482, 2804,
3253, 2979, 2458, 2306, 2482, 3209, 3915, 1292, 931, 2748, 2874, 2089,
2660, 3205, 3093, 1389, 834, 1914, 2568, 2831, 2129, 3138, 2841, 2318,
2653, 1598, 1779, 1529, 2190, 2180, 1737, 1845, 2511, 1922, 3679, 3277,
2633, 2064, 2802, 2853, 2220, 1987, 2491, 1867, 3593, 1998, 2425, 3226,
2143, 3466, 3327, 3283, 3011, 2552, 2844, 2501, 1575, 1829, 3086, 3345,
1905, 1192, 2772, 3667, 4223, 4117, 2113, 2312, 2615, 3126, 2581, 3265,
3682, 3355, 1820, 2989, 2806, 3333, 2395, 2777, 2189, 2628, 2379, 1867])
time = range(1, len(series) 1)
#%% Prepare Data for NN
def windowed_dataset(series, window_size, batch_size, shuffle_buffer):
dataset = tf.data.Dataset.from_tensor_slices(series)
dataset = dataset.window(window_size 1, shift=1, drop_remainder=True)
dataset = dataset.flat_map(lambda window: window.batch(window_size 1))
dataset = dataset.shuffle(shuffle_buffer).map(lambda window: (window[:-4], window[-1])) # :-4 because we want to predict the value in 4 weeks, not for the next week
dataset = dataset.batch(batch_size).prefetch(1)
return dataset
split_time = len(time)-16
time_train = time[:split_time]
x_train = series[:split_time]
# For normalization based on training data, so that model does not "see" the validation data before validation
train_mean = x_train.mean()
train_std = x_train.std()
x_train_norm = (x_train - train_mean) / train_std
series_norm = (series - train_mean) / train_std
time_valid = time[split_time:]
x_valid = series[split_time:]
def plot_series(time, series, format="-", start=0, end=None):
plt.plot(time[start:end], series[start:end], format)
plt.xlabel("Time")
plt.ylabel("Value")
plt.grid(True)
plt.figure(figsize=(10, 6))
plot_series(time_train, x_train)
plt.show()
plt.figure(figsize=(10, 6))
plot_series(time_valid, x_valid)
plt.show()
#%% Build the dataset
w_size = 4
b_size = 4
sb_size = 1
w_size_adjusted = w_size - 3
dataset = windowed_dataset(series_norm, window_size = w_size, batch_size = b_size, shuffle_buffer = sb_size)
#%% Build and train the model
l0 = tf.keras.layers.Dense(1, input_shape=[w_size_adjusted])
model = tf.keras.models.Sequential([l0])
model.compile(loss="mse", optimizer=tf.keras.optimizers.SGD(learning_rate=1e-6, momentum=0.9)) # original: learning_rat = 1e-6, also trid [... ].optimizers.Adam(learning_rate=1e-6)
model.fit(dataset,epochs=100,verbose=0)
#%% Forecast data
forecast = []
for time_step in range(len(series) - w_size_adjusted 1):
forecast.append(model.predict(series_norm[time_step:time_step w_size_adjusted][np.newaxis]))
forecast_subset = forecast[split_time - w_size_adjusted 1:]
results_norm = np.array(forecast_subset)[:, 0, 0]
#%% Unnormalize
results = (results_norm * train_std) train_mean
#%% Plot
plt.figure(figsize=(10, 6))
plot_series(time_valid, x_valid)
plot_series(time_valid, results)
plt.title('window_size: {0}, batch_size: {1}, shuffle_buffer: {2}'.format(w_size, b_size, sb_size))
CodePudding user response:
Using this does the trick
l0 = tf.keras.layers.Dense(1, input_shape=[w_size_adjusted], kernel_initializer="ones")
Essentially, initial weight values make too much of an impact because of too few training data.