Consider Graviton3, for example. It's a 64-core CPU with per-core caches 64KiB L1d and 1MiB L2. And a shared L3 of 64MiB across all cores. The RAM bandwidth per socket is 307GB/s (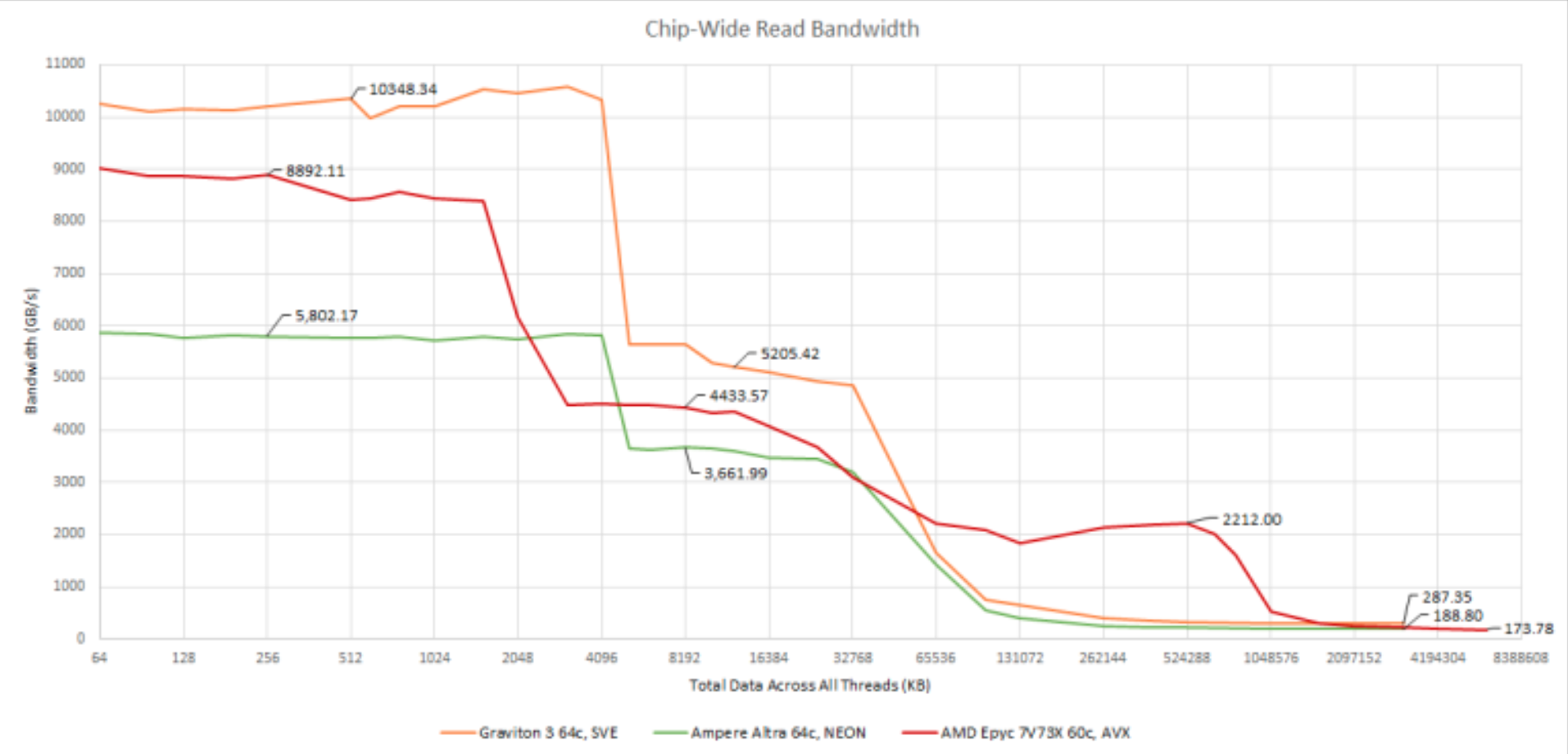
we see that all-cores bandwidth drops off to roughly half, when the data exceeds 4MB. This makes sense: 64x 64KiB = 4 MiB is the size of the L1 data cache.
But why does the next cliff begin at 32MB? And why is the drop-off so gradual there? The private L2 caches of 64 cores is a total of 64 MiB, same as the shared L3 size.
CodePudding user response:
It looks from the plot like they may not have tested any sizes between 32M and 64M. Looks like a straight line between those points on all 3 CPUs.
Since 64M is the total size of both L2 and L3, I'd expect a test like this to have slowed most of the way down at 64M. As Brendan says, page tables and a bit of code will take space, competing with the actual intended test data. If the benchmark loop is tight, stack won't come into play, except for interrupt handling.
Once you're evicting anything from a working set slightly larger than cache, you often evict almost everything before getting back to it, depending on pseudo-LRU luck. I'd expect a test size or 48 or even 56 MiB to be a lot closer to the 32 MiB data point than the 64 MiB data point.
CodePudding user response:
Can all of L2/L3 cache be used by data?
In theory, yes; but only if there's no "non-data" (code) in the cache, only if you count "all data" (and don't just count a process' data and ignore things like stack and page tables), and only if there isn't any aliasing problems.
But why does the next cliff begin at 32MB? And why is the drop-off so gradual there?
For a fully associative cache I'd expect a sudden drop off at/near 32 MiB. However, large caches are almost never fully associative as it costs way to much to find anything in the cache.
As associativity decreases the chance of conflicts increases. For example, for an 8-way associative 64 MiB cache the pathological case is that everything conflicts and you're only able to effectively use 8 MiB of it.
More specifically, for a 64 MiB cache (with unknown associativity), and an "assumed Linux" environment that lacks support for cache coloring, it's reasonable to expect a smooth drop off that ends at 64 MiB.