I try to scrape the yearly total revenues from yahoo finance using pandas and yahoo_fin by using the following code:
from yahoo_fin import stock_info as si
import yfinance as yf
import pandas as pd
tickers = ('AAPL', 'MSFT', 'IBM')
income_statements_yearly= [] #All numbers in thousands
for ticker in tickers:
income_statement = si.get_income_statement(ticker, yearly=True)
years = income_statement.columns
income_statement.insert(loc=0, column='Ticker', value=ticker)
for i in range(4):
#print(years[i].year)
income_statement.rename(columns = {years[i]:years[i].year}, inplace = True)
income_statements_yearly.append(income_statement)
income_statements_yearly = pd.concat(income_statements_yearly)
income_statements_yearly
The result I get looks like:
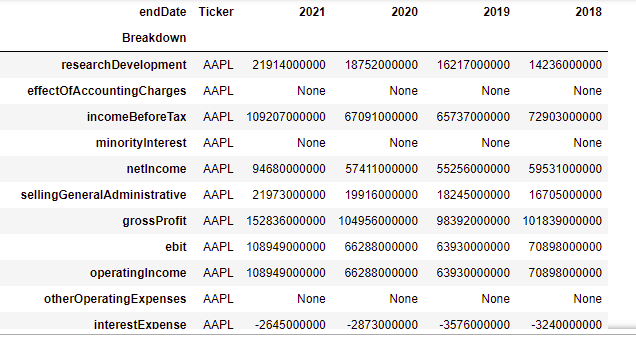
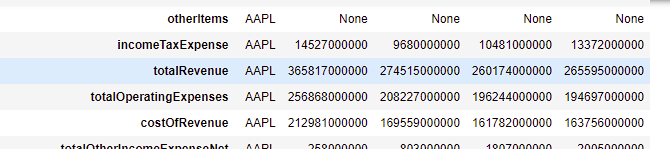
I would like to create on that basis another dataframe revenues and reduce the dataframe to only the row totalRevenue instead of getting all rows and at the same time I would love to rename the columns 2021, 2020, 2019, 2018 to revenues_2021, revenues_2020, revenues_2019, revenues_2018.
The result shall look like:
df = pd.DataFrame({'Ticker': ['AAPL', 'MSFT', 'IBM'],
'revenues_2021': [365817000000, 168088000000, 57351000000],
'revenues_2020': [274515000000, 143015000000, 55179000000],
'revenues_2019': [260174000000, 125843000000, 57714000000],
'revenues_2018': [265595000000, 110360000000, 79591000000]})
How can I solve this in an easy and fast way?
Ty for your help in advance.
CodePudding user response:
CODE
revenues = income_statements_yearly.loc["totalRevenue"].reset_index(drop=True)
revenues.columns = ["Ticker"] ["revenues_" str(col) for col in revenues.columns if col != "Ticker"]
OUTPUT
Ticker revenues_2021 revenues_2020 revenues_2019 revenues_2018
0 AAPL 365817000000 274515000000 260174000000 265595000000
1 MSFT 168088000000 143015000000 125843000000 110360000000
2 IBM 57351000000 55179000000 57714000000 79591000000