I'm trying to achieve a dataframe transformation (kinda complicated for me) with Pandas, see image below.
The original dataframe source is an Excel sheet (here is an 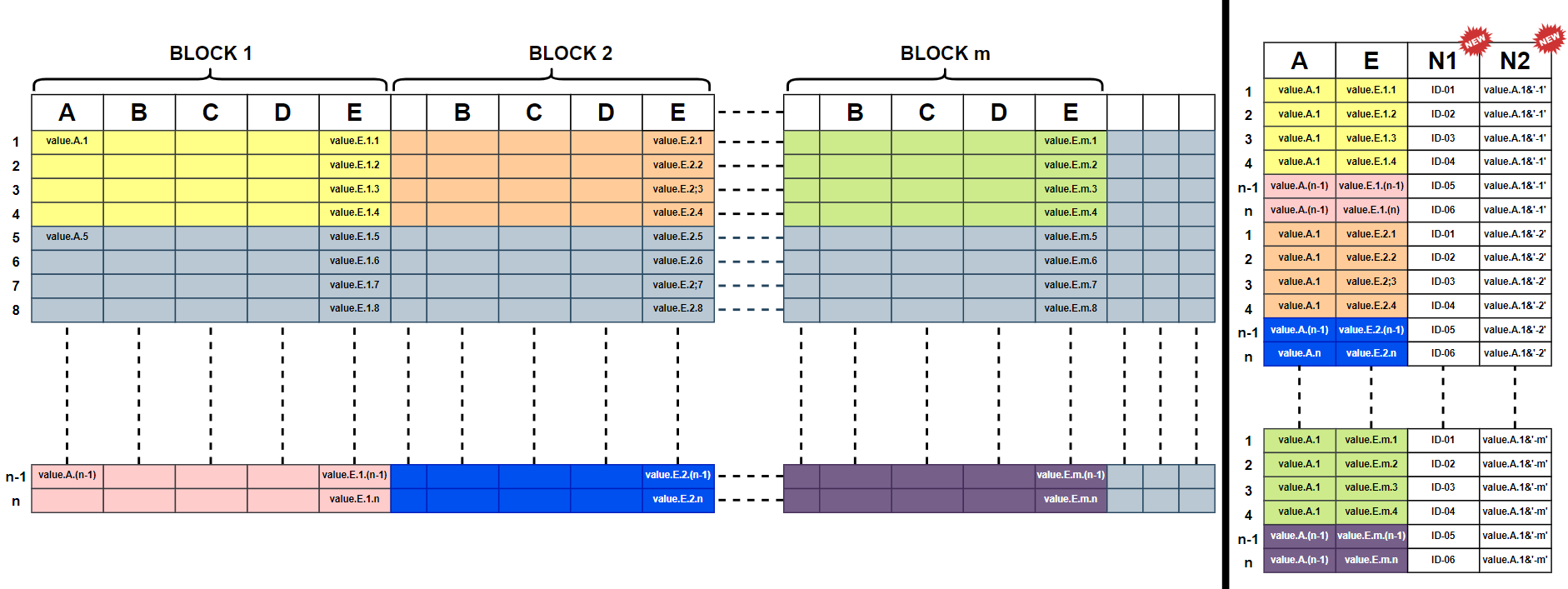
Basically, I need to do these transformations by order :
- Select (in each block) the first four lines the last two lines
- Stack all the blocks together
- Drop the last three unnamed columns
- Select columns A and E
- Fill down the column A
- Create a new column N1 that holds a sequence of values (ID-01 to ID-06)
- Create a new column N2 that concatente the first value of the block and its number
And for that, I made this code who unfortunately return a [0 rows × 56 columns] dataframe :
import pandas as pd
myFile = r"C:\Users\wasp_96b\Desktop\ExcelSheet.xlsx"
df1 = pd.read_excel(myFile, sheet_name = 'Sheet1')
df2 = (pd.wide_to_long(df1.reset_index(), 'A' ,i='index',j='value').reset_index(drop=True))
df2.ffill(axis = 0)
df2.insert(2, 'N1', 'ID-' str(range(1, 1 len(df2))))
df2.insert(3, 'N2', len(df2)//5)
display(df2)
Do you have any idea or explanation for this scenario ?
Is there any other ways I can obtain the result I'm looking for ?
CodePudding user response:
The Column names in your code and in the data are not matching. However, from the data and the output you desire, I think I am able to solve your query. The code is very specific for the data you provided and you might need to change it later
CODE
import pandas as pd
myFile = "ExcelSheet.xlsx"
df = pd.read_excel(myFile, sheet_name='Sheet1')
# Forwad filling the column
df["Housing"] = df["Housing"].ffill()
# Select the first 4 lines and last two lines
df = pd.concat([df.head(4), df.tail(2)]).reset_index(drop=True)
# Drop the unneccsary columns
df = df.drop(columns=[col for col in df.columns if not (col.startswith("Elements") or col == "Housing")])
df.rename(columns={"Elements": "Elements.0"}, inplace=True)
# Stack all columns
df = pd.wide_to_long(df.reset_index(), stubnames=["Elements."], i="index", j="N2").reset_index("N2")
df.rename(columns={"Elements.": "Elements"}, inplace=True)
# Adding N1 and N2
df["N1"] = "ID_" (df.index 1).astype("str")
df["N2"] = df["Housing"] "-" (df["N2"] 1).astype("str")
# Finishing up
df = df[["Housing", "Elements", "N1", "N2"]].reset_index(drop=True)
print(df.head(12))
OUTPUT(only first 12 rows)
Housing Elements N1 N2
0 OID1 1 ID_1 OID1-1
1 OID1 M-0368 ID_2 OID1-1
2 OID1 JUM ID_3 OID1-1
3 OID1 NODE-1 ID_4 OID1-1
4 OID4 BTM-B ID_5 OID4-1
5 OID4 1 ID_6 OID4-1
6 OID1 1 ID_1 OID1-2
7 OID1 M-0379 ID_2 OID1-2
8 OID1 JUM ID_3 OID1-2
9 OID1 NODE-2 ID_4 OID1-2
10 OID4 BTM-B ID_5 OID4-2
11 OID4 2 ID_6 OID4-2