I am using two methods (random tree and neural network) to calculate whether is person is suceptible to a certain disease, hence binary classification. After I run my code, I am getting a good f1-score for identitying the non-suceptible, for a terrible f1-score for identitying the suceptible:
precision recall f1-score support (Random Tree)
0 0.86 0.99 0.92 711
1 0.33 0.04 0.08 117
precision recall f1-score support (Neural Network)
0 0.89 0.89 0.89 711
1 0.31 0.30 0.30 117
I have tried a few things to increase the f-1 score, but to no avail:
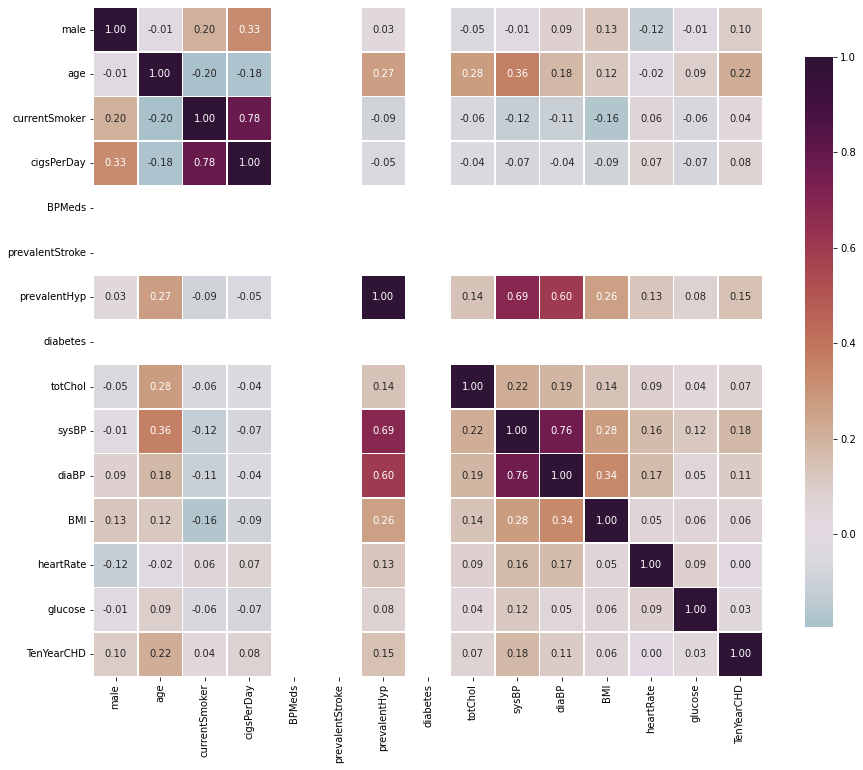
- Removing features that don't strongly correlate with the label
- Removing features that have significant outliers
- Increasing size of neural network (added extra layer, f1-score went from 0.23 to 0.30)
What are other possible reasons why my f1-score for predicting suceptibility is terrible?
#Random Forest
rf = RandomForestRegressor(n_estimators = 199, random_state = 4)
rf.fit(X_train_scaled, y_train)
predictions = rf.predict(X_val_scaled)
y_val_hat_cat_rf = (rf.predict(X_val_scaled) > 0.5)
#Neural Network
model = keras.Sequential()
model.add(Dense(11, activation='relu'))
model.add(Dense(7,activation='relu'))
model.add(Dense(4,activation='relu'))
model.add(Dense(1, activation='sigmoid'))
hp_learning_rate = 0.01
model.compile(optimizer=keras.optimizers.Adam(learning_rate=hp_learning_rate),
loss=keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
model.fit(X_train_scaled,y_train,epochs=1000,verbose=0)
J_list = model.history.history['loss']
plt.plot(J_list)
val_acc_per_epoch = model.history.history['accuracy']
CodePudding user response:
Your random forest model is a regression one. You probably meant RandomForestClassifier().
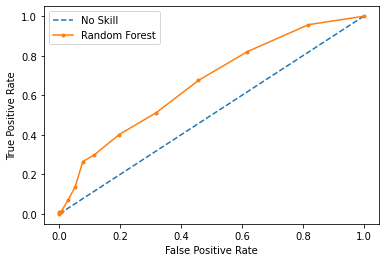
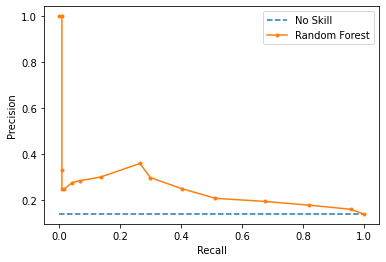
F-measure is threshold sensitive (which is unlikely to be 0.5 in this case). If F1 is truly your designated metric, you should study precision-recall curve for the proper threshold selection.
For a quick check you may also try class_weight='balanced' for RandomForestClassifier. Resampling your dataset would likely be excessive, but if you're only interested in the positive class, you may consider it. (This is frowned upon by statisticians, but so is using F1 for evaluation.)